Basically, a regular expression is a pattern describing a certain amount of text. Their name comes from the mathematical theory on which they are based. But we will not dig into that. You will usually find the name abbreviated to "regex" or "regexp". This tutorial uses "regex", because it is easy to pronounce the plural "regexes". On this website, regular expressions are highlighted in red as regex .
This first example is actually a perfectly valid regex. It is the most basic pattern, simply matching the literal text regex . A "match" is the piece of text, or sequence of bytes or characters that pattern was found to correspond to by the regex processing software. Matches are highlighted in blue on this site.
\b [ A - Z 0 - 9 ._%+ - ] + @ [ A - Z 0 - 9 . - ] + \. [ A - Z ] {2,} \b is a more complex pattern. It describes a series of letters, digits, dots, underscores, percentage signs and hyphens, followed by an at sign, followed by another series of letters, digits and hyphens, finally followed by a single dot and two or more letters. In other words: this pattern describes an email address . This also shows the syntax highlighting applied to regular expressions on this site. Word boundaries and quantifiers are blue, character classes are orange, and escaped literals are gray. You'll see additional colors like green for grouping and purple for meta tokens later in the tutorial.
With the above regular expression pattern, you can search through a text file to find email addresses, or verify if a given string looks like an email address. This tutorial uses the term "string" to indicate the text that the regular expression is applied to. This website highlights them in green . The term "string" or "character string" is used by programmers to indicate a sequence of characters. In practice, you can use regular expressions with whatever data you can access using the application or programming language you are working with.
A regular expression "engine" is a piece of software that can process regular expressions, trying to match the pattern to the given string. Usually, the engine is part of a larger application and you do not access the engine directly. Rather, the application invokes it for you when needed, making sure the right regular expression is applied to the right file or data.
As usual in the software world, different regular expression engines are not fully compatible with each other. The syntax and behavior of a particular engine is called a regular expression flavor. This tutorial covers all the popular regular expression flavors, including Perl , PCRE , PHP , .NET , Java , JavaScript , XRegExp , VBScript , Python , Ruby , Delphi , R , Tcl , POSIX , and many others . The tutorial alerts you when these flavors require different syntax or show different behavior. Even if your application is not explicitly covered by the tutorial, it likely uses a regex flavor that is covered, as most applications are developed using one of the programming environments or regex libraries just mentioned.
You can easily try the following yourself in a text editor that supports regular expressions, such as EditPad Pro . If you do not have such an editor, you can download the free evaluation version of EditPad Pro to try this out. EditPad Pro's regex engine is fully functional in the demo version.
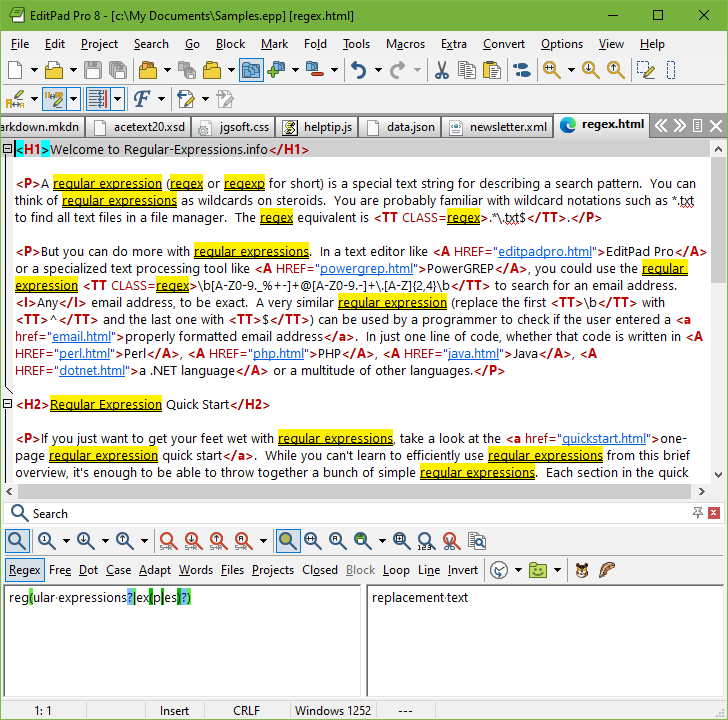
As a quick test, copy and paste the text of this page into EditPad Pro. Then select Search|Multiline Search Panel in the menu. In the search panel that appears near the bottom, type in regex in the box labeled "Search Text". Mark the "Regular expression" checkbox, and click the Find First button. This is the leftmost button on the search panel. See how EditPad Pro's regex engine finds the first match. Click the Find Next button, which sits next to the Find First button, to find further matches. When there are no further matches, the Find Next button's icon flashes briefly.
Now try to search using the regex reg ( ular expression s ? | ex ( p | es ) ? ) . This regex finds all names, singular and plural, I have used on this page to say "regex". If we only had plain text search, we would have needed 5 searches. With regexes, we need just one search. Regexes save you time when using a tool like EditPad Pro. Select Count Matches in the Search menu to see how many times this regular expression can match the file you have open in EditPad Pro.
If you are a programmer, your software will run faster since even a simple regex engine applying the above regex once will outperform a state of the art plain text search algorithm searching through the data five times. Regular expressions also reduce development time. With a regex engine, it takes only one line (e.g. in Perl, PHP, Python, Ruby, Java, or .NET) or a couple of lines (e.g. in C using PCRE) of code to, say, check if the user's input looks like a valid email address .
Regex Tutorial Table of Contents
This regular expressions tutorial teaches you every aspect of regular expressions. Each topic assumes you have read and understood all previous topics. If you are new to regular expressions, you should read the topics in the order presented.
The introduction indicates the scope of the tutorial and which regex flavors are discussed. It also introduces basic terminology.
Literal Characters and Special Characters
The simplest regex consists of only literal characters. Certain characters have special meanings in a regex and have to be escaped. Escaping rules may get a bit complicated when using regexes in software source code.
Non-printable characters such as control characters and special spacing or line break characters are easier to enter using control character escapes or hexadecimal escapes.
How a Regex Engine Works Internally
First look at the internals of the regular expression engine's internals. Later topics build on this information. Knowing the engine's internals greatly helps you to craft regexes that match what you intended, and not match what you do not want.
Character Classes or Character Sets
A character class or character set matches a single character out of several possible characters, consisting of individual characters and/or ranges of characters. A negated character class matches a single character not in the character class.
Shorthand character classes allow you to use common sets of characters quickly. You can use shorthands on their own or as part of character classes.
Character class subtraction allows you to match one character that is present in one set of characters but not present in another set of characters.
Character class intersection allows you to match one character that is present in one set of characters and also present in another set of characters.
The dot matches any character, though usually not line break characters unless you change an option.
Anchors are zero-length. They do not match any characters, but rather a position. There are anchors to match at the start and end of the subject string, and anchors to match at the start and end of each line.
Word boundaries are like anchors, but match at the start of a word and/or the end of a word.
By separating different sub-regexes with vertical bars, you can tell the regex engine to attempt them from left to right, and return success as soon as one of them can be matched.
Putting a question mark after an item tells the regex engine to match the item if possible, but continue anyway (rather than admit defeat) if it cannot be matched.
Repetition Using Various Quantifiers
Three styles of operators, the star, the plus, and curly braces, allow you to repeat an item zero or more times, once or more, or an arbitrary number of times. It is important to understand that these quantifiers are "greedy" by default, unless you explicitly make them "lazy".
By placing parentheses around part of the regex, you tell the engine to treat that part as a single item when applying quantifiers or to group alternatives together. Parentheses also create capturing groups allow you to reuse the text matched by part of the regex.
Backreferences to capturing groups match the same text that was previously matched by that capturing group, allowing you to match patterns of repeated text.
Named Groups and Backreferences
Regular expressions that have multiple groups are much easier to read and maintain if you use named capturing groups and named backreferences.
When using alternation to match different variants of the same thing, you can put the alternatives in a branch reset group. Then all the alternatives share the same capturing groups. This allows you to use backreferences or retrieve part of the matched text without having to check which of the alternatives captured it.
Splitting a regular expression into multiple lines, adding comments and whitespace, makes it easier to read and understand.
Unicode Characters and Properties
If your regular expression flavor supports Unicode, then you can use special Unicode regex tokens to match specific Unicode characters, or to match any character that has a certain Unicode property or is part of a particular Unicode script or block.
Change matching modes such as "case insensitive" for specific parts of the regular expression.
Atomic Grouping and Possessive Quantifiers
Nested quantifiers can cause an exponentially increasing amount of backtracking that brings the regex engine to a grinding halt. Atomic grouping and possessive quantifiers provide a solution.
Lookaround with Zero-Length Assertions , part 1 and part 2
With lookahead and lookbehind, collectively called lookaround, you can find matches that are followed or not followed by certain text, and preceded or not preceded by certain text, without having the preceding or following text included in the overall regex match. You can also use lookaround to test the same part of the match for multiple requirements.
Keep The Text Matched So Far out of The Overall Regex Match
Keeping the text matched so far out of the overall regex match allows you to find matches that are preceded by certain text, without having that preceding text included in the overall regex match. This method is primarily of interest with regex flavors that have no or limited support for lookbehind.
A conditional is a special construct that first evaluates a lookaround or backreference, and then execute one sub-regex if the lookaround succeeds, and another sub-regex if the lookaround fails.
Recursion matches the whole regex again at a particular point inside the regex, which makes it possible to match balanced constructs.
Subroutine calls allow you to write regular expressions that match the same constructs in multiple places without having to duplicate parts of your regular expression.
Recursion, Subroutines, & Capturing
Capturing groups inside recursion and subroutine calls are handled differently by the regex flavors that support them.
Backreferences with Recursion Level
Special backreferences match the text stored by a capturing group at a particular recursion level, instead of the text most recently matched by that capturing group.
Recursion, Subroutines, & Backtracking
The regex flavors that support recursion and subroutine calls backtrack differently after a recursion or subroutine call fails.
If you are using a POSIX-compliant regular expression engine, you can use POSIX bracket expressions to match locale-dependent characters.
Issues with Zero-Length Matches
When a regex can find zero-length matches, regex engines use different strategies to avoid getting stuck on a zero-length match when you want to iterate over all matches in a string. This may lead to different match results.
Continuing from The Previous Match Attempt
Forcing a regex match to start at the end of a previous match provides an efficient way to parse text data.
The most basic regular expression consists of a single literal character, such as a . It matches the first occurrence of that character in the string. If the string is Jack is a boy , it matches the a after the J . The fact that this a is in the middle of the word does not matter to the regex engine. If it matters to you, you will need to tell that to the regex engine by using word boundaries . We will get to that later.
This regex can match the second a too. It only does so when you tell the regex engine to start searching through the string after the first match. In a text editor, you can do so by using its "Find Next" or "Search Forward" function. In a programming language, there is usually a separate function that you can call to continue searching through the string after the previous match.
Similarly, the regex cat matches cat in About cats and dogs . This regular expression consists of a series of three literal characters. This is like saying to the regex engine: find a c , immediately followed by an a , immediately followed by a t .
Note that regex engines are case sensitive by default. cat does not match Cat , unless you tell the regex engine to ignore differences in case.
Because we want to do more than simply search for literal pieces of text, we need to reserve certain characters for special use. In the regex flavors discussed in this tutorial , there are 12 characters with special meanings: the backslash \ , the caret ^ , the dollar sign $ , the period or dot . , the vertical bar or pipe symbol | , the question mark ? , the asterisk or star * , the plus sign + , the opening parenthesis ( , the closing parenthesis ) , the opening square bracket [ , and the opening curly brace { , These special characters are often called "metacharacters". Most of them are errors when used alone.
If you want to use any of these characters as a literal in a regex, you need to escape them with a backslash. If you want to match 1+1=2 , the correct regex is 1 \+ 1=2 . Otherwise, the plus sign has a special meaning.
Note that 1 + 1=2 , with the backslash omitted, is a valid regex. So you won't get an error message. But it doesn't match 1+1=2 . It would match 111=2 in 123+111=234 , due to the special meaning of the plus character .
If you forget to escape a special character where its use is not allowed, such as in + 1 , then you will get an error message.
Most regular expression flavors treat the brace { as a literal character, unless it is part of a repetition operator like a {1,3} . So you generally do not need to escape it with a backslash, though you can do so if you want. But there are a few exceptions. Java requires literal opening braces to be escaped. Boost and std::regex require all literal braces to be escaped.
] is a literal outside character classes . Different rules apply inside character classes. Those are discussed in the topic about character classes. Again, there are exceptions. std::regex and Ruby require closing square brackets to be escaped even outside character classes.
All other characters should not be escaped with a backslash. That is because the backslash is also a special character. The backslash in combination with a literal character can create a regex token with a special meaning. E.g. \d is a shorthand that matches a single digit from 0 to 9 .
Escaping a single metacharacter with a backslash works in all regular expression flavors. Some flavors also support the … escape sequence. All the characters between the and the are interpreted as literal characters. E.g. *\d+* matches the literal text *\d+* . The \E may be omitted at the end of the regex, so *\d+* is the same as *\d+* . This syntax is supported by the JGsoft engine , Perl , PCRE , PHP , Delphi , Java , both inside and outside character classes . Java 4 and 5 have bugs that cause … to misbehave, however, so you shouldn't use this syntax with Java. Boost supports it outside character classes, but not inside.
If you are a programmer, you may be surprised that characters like the single quote and double quote are not special characters. That is correct. When using a regular expression or grep tool like PowerGREP or the search function of a text editor like EditPad Pro, you should not escape or repeat the quote characters like you do in a programming language.
In your source code, you have to keep in mind which characters get special treatment inside strings by your programming language. That is because those characters are processed by the compiler, before the regex library sees the string. So the regex 1 \+ 1=2 must be written as "1\\+1=2" in C++ code. The C++ compiler turns the escaped backslash in the source code into a single backslash in the string that is passed on to the regex library. To match c:\temp , you need to use the regex c: \\ temp . As a string in C++ source code, this regex becomes "c:\\\\temp" . Four backslashes to match a single one indeed.
See the tools and languages section of this website for more information on how to use regular expressions in various programming languages.
You can use special character sequences to put non-printable characters in your regular expression. Use \t to match a tab character (ASCII 0x09), \r for carriage return (0x0D) and \n for line feed (0x0A). More exotic non-printables are \a (bell, 0x07), \e (escape, 0x1B), and \f (form feed, 0x0C). Remember that Windows text files use \r\n to terminate lines, while UNIX text files use \n .
In some flavors, \v matches the vertical tab (ASCII 0x0B). In other flavors, \v is a shorthand that matches any vertical whitespace character. That includes the vertical tab, form feed, and all line break characters. Perl 5.10, PCRE 7.2, PHP 5.2.4, R, Delphi XE, and later versions treat it as a shorthand. Earlier versions treated it as a needlessly escaped literal v. The JGsoft flavor originally matched only the vertical tab with \v . JGsoft V2 matches any vertical whitespace with \v .
Many regex flavors also support the tokens \cA through \cZ to insert ASCII control characters. The letter after the backslash is always a lowercase c. The second letter is an uppercase letter A through Z, to indicate Control+A through Control+Z. These are equivalent to \x01 through \x1A (26 decimal). E.g. \cM matches a carriage return, just like \r , \x0D , and \u000D . Most flavors allow the second letter to be lowercase, with no difference in meaning. Only Java requires the A to Z to be uppercase.
Using characters other than letters after \c is not recommended because the behavior is inconsistent between applications. Some allow any character after \c while other allow ASCII characters. The application may take the last 5 bits that character index in the code page or its Unicode code point to form an ASCII control character. Or the application may just flip bit 0x40. Either way \c@ through \c_ would match control characters 0x00 through 0x1F. But \c* might match a line feed or the letter j . The asterisk is character 0x2A in the ASCII table, so the lower 5 bits are 0x0A while flipping bit 0x40 gives 0x6A. Metacharacters indeed lose their meaning immediately after \c in applications that support \cA through \cZ for matching control characters. The original JGsoft flavor, .NET , and XRegExp are more sensible. They treat anything other than a letter after \c as an error.
In XML Schema regular expressions and XPath , \c is a shorthand character class that matches any character allowed in an XML name.
The JGsoft flavor originally treated \cA through \cZ as control characters. But JGsoft V2 treats \c as an XML shorthand.
If your regular expression engine supports Unicode , you can use \uFFFF or \x{FFFF} to insert a Unicode character. The euro currency sign occupies Unicode code point U+20AC. If you cannot type it on your keyboard, you can insert it into a regular expression with \u20AC or \x{20AC} . See the tutorial section on Unicode for more details on matching Unicode code points .
If your regex engine works with 8-bit code pages instead of Unicode, then you can include any character in your regular expression if you know its position in the character set that you are working with. In the Latin-1 character set, the copyright symbol is character 0xA9. So to search for the copyright symbol, you can use \xA9 . Another way to search for a tab is to use \x09 . Note that the leading zero is required. In Tcl 8.5 and prior you have to be careful with this syntax, because Tcl used to eat up all hexadecimal characters after \x and treat the last 4 as a Unicode code point. So \xA9ABC20AC would match the euro symbol. Tcl 8.6 only takes the first two hexadecimal digits as part of the \x , as all other regex flavors do, so \xA9 ABC20AC matches ©ABC20AC .
Many applications also support octal escapes in the form of \0377 or \377 , where 377 is the octal representation of the character's position in the character set (255 decimal in this case). There is a lot of variation between regex flavors as to the number of octal digits allowed or required after the backslash, whether the leading zero is required or not allowed, and whether \0 without additional digits matches a NULL byte. In some flavors this causes complications as \1 to \77 can be octal escapes 1 to 63 (decimal) or backreferences 1 to 77 (decimal), depending on how many capturing groups there are in the regex. Therefore, using these octal escapes in regexes is strongly discouraged. Use hexadecimal escapes instead.
Perl 5.14, PCRE 8.34, PHP 5.5.10, and R 3.0.3 support a new syntax \o{377} for octal escapes. You can have any number of octal digits between the curly braces, with or without leading zero. There is no confusion with backreferences and literal digits that follow are cleanly separated by the closing curly brace. Do be careful to only put octal digits between the curly braces. In Perl, \o{whatever} is not an error but matches a NULL byte.
The JGsoft flavor originally supported octal escapes in the form of \0377 . JGsoft V2 supports \o{377} and treats \0377 as an error.
Many programming languages support similar escapes for non-printable characters in their syntax for literal strings in source code. Then such escapes are translated by the compiler into their actual characters before the string is passed to the regex engine. If the regex engine does not support the same escapes, this can cause an apparent difference in behavior when a regex is specified as a literal string in source code compared with a regex that is read from a file or received from user input. For example, POSIX regular expressions do not support any of these escapes. But the C programming language does support escapes like \n and \x0A in string literals. So when developing an application in C using the POSIX library, \n is only interpreted as a newline when you add the regex as a string literal to your source code. Then the compiler interprets \n and the regex engine sees an actual newline character. If your code reads the same regex from a file, then the regex engine sees \n . Depending on the implementation, the POSIX library interprets this as a literal n or as an error. The actual POSIX standard states that the behavior of an "ordinary" character preceded by a backslash is "undefined".
A similar issue exists in Python 3.2 and prior with the Unicode escape \uFFFF . Python has supported this syntax as part of (Unicode) string literals ever since Unicode support was added to Python. But Python's re module only supports \uFFFF starting with Python 3.3. In Python 3.2 and earlier, \uFFFF works when you add your regex as a literal (Unicode) string to your Python code. But when your Python 3.2 script reads the regex from a file or user input, \u FFFF matches uFFFF literally as the regex engine sees \u as an escaped literal u .
Knowing how the regex engine works enables you to craft better regexes more easily. It helps you understand quickly why a particular regex does not do what you initially expected. This saves you lots of guesswork and head scratching when you need to write more complex regexes.
After introducing a new regex token, this tutorial explains step by step how the regex engine actually processes that token. This inside look may seem a bit long-winded at certain times. But understanding how the regex engine works enables you to use its full power and help you avoid common mistakes.
While there are many implementations of regular expressions that differ sometimes slightly and sometimes significantly in syntax and behavior, there are basically only two kinds of regular expression engines: text-directed engines, and regex-directed engines. Nearly all modern regex flavors are based on regex-directed engines. This is because certain very useful features, such as lazy quantifiers and backreferences , can only be implemented in regex-directed engines.
A regex-directed engine walks through the regex, attempting to match the next token in the regex to the next character. If a match is found, the engine advances through the regex and the subject string. If a token fails to match, the engine backtracks to a previous position in the regex and the subject string where it can try a different path through the regex. This tutorial will talk a lot more about backtracking later on. Modern regex flavors using regex-directed engines have lots of features such as atomic grouping and possessive quantifiers that allow you to control this backtracking.
A text-directed engine walks through the subject string, attempting all permutations of the regex before advancing to the next character in the string. A text-directed engine never backtracks. Thus, there isn't much to discuss about the matching process of a text-directed engine. In most cases, a text-directed engine finds the same matches as a regex-directed engine.
When this tutorial talks about regex engine internals, the discussion assumes a regex-directed engine. It only mentions text-directed engines in situations where they find different matches. And that only really happens when your regex uses alternation with two alternatives that can match at the same position.
This is a very important point to understand: a regex engine always returns the leftmost match, even if a "better" match could be found later. When applying a regex to a string, the engine starts at the first character of the string. It tries all possible permutations of the regular expression at the first character. Only if all possibilities have been tried and found to fail, does the engine continue with the second character in the text. Again, it tries all possible permutations of the regex, in exactly the same order. The result is that the regex engine returns the leftmost match.
When applying cat to He captured a catfish for his cat. , the engine tries to match the first token in the regex c to the first character in the match H . This fails. There are no other possible permutations of this regex, because it merely consists of a sequence of literal characters. So the regex engine tries to match the c with the e . This fails too, as does matching the c with the space. Arriving at the 4th character in the string, c matches c . The engine then tries to match the second token a to the 5th character, a . This succeeds too. But then, t fails to match p . At that point, the engine knows the regex cannot be matched starting at the 4th character in the string. So it continues with the 5th: a . Again, c fails to match here and the engine carries on. At the 15th character in the string, c again matches c . The engine then proceeds to attempt to match the remainder of the regex at character 15 and finds that a matches a and t matches t .
The entire regular expression could be matched starting at character 15. The engine is "eager" to report a match. It therefore reports the first three letters of catfish as a valid match. The engine never proceeds beyond this point to see if there are any "better" matches. The first match is considered good enough.
In this first example of the engine's internals, our regex engine simply appears to work like a regular text search routine. However, it is important that you can follow the steps the engine takes in your mind. In following examples, the way the engine works has a profound impact on the matches it finds. Some of the results may be surprising. But they are always logical and predetermined, once you know how the engine works.
With a "character class", also called "character set", you can tell the regex engine to match only one out of several characters. Simply place the characters you want to match between square brackets. If you want to match an a or an e, use [ ae ] . You could use this in gr [ ae ] y to match either gray or grey . Very useful if you do not know whether the document you are searching through is written in American or British English.
A character class matches only a single character. gr [ ae ] y does not match graay , graey or any such thing. The order of the characters inside a character class does not matter. The results are identical.
You can use a hyphen inside a character class to specify a range of characters. [ 0 - 9 ] matches a single digit between 0 and 9. You can use more than one range. [ 0 - 9 a - f A - F ] matches a single hexadecimal digit, case insensitively. You can combine ranges and single characters. [ 0 - 9 a - f x A - F X ] matches a hexadecimal digit or the letter X. Again, the order of the characters and the ranges does not matter.
Character classes are one of the most commonly used features of regular expressions. You can find a word, even if it is misspelled, such as sep [ ae ] r [ ae ] te or li [ cs ] en [ cs ] e . You can find an identifier in a programming language with [ A - Z a - z _ ] [ A - Z a - z _ 0 - 9 ] * . You can find a C-style hexadecimal number with 0 [ xX ] [ A - F a - f 0 - 9 ] + .
Typing a caret after the opening square bracket negates the character class. The result is that the character class matches any character that is not in the character class. Unlike the dot , negated character classes also match (invisible) line break characters. If you don't want a negated character class to match line breaks, you need to include the line break characters in the class. [ ^ 0 - 9 \r \n ] matches any character that is not a digit or a line break.
It is important to remember that a negated character class still must match a character. q [ ^ u ] does not mean: "a q not followed by a u". It means: "a q followed by a character that is not a u". It does not match the q in the string Iraq . It does match the q and the space after the q in Iraq is a country . Indeed: the space becomes part of the overall match, because it is the "character that is not a u" that is matched by the negated character class in the above regexp. If you want the regex to match the q, and only the q, in both strings, you need to use negative lookahead : q (?! u ) . But we will get to that later.
In most regex flavors, the only special characters or metacharacters inside a character class are the closing bracket ] , the backslash \ , the caret ^ , and the hyphen - . The usual metacharacters are normal characters inside a character class, and do not need to be escaped by a backslash. To search for a star or plus, use [ +* ] . Your regex will work fine if you escape the regular metacharacters inside a character class, but doing so significantly reduces readability.
To include a backslash as a character without any special meaning inside a character class, you have to escape it with another backslash. [ \\ x ] matches a backslash or an x. The closing bracket ] , the caret ^ and the hyphen - can be included by escaping them with a backslash, or by placing them in a position where they do not take on their special meaning. The POSIX and GNU flavors are an exception. They treat backslashes in character classes as literal characters. So with these flavors, you can't escape anything in character classes.
To include an unescaped caret as a literal, place it anywhere except right after the opening bracket. [ x^ ] matches an x or a caret. This works with all flavors discussed in this tutorial.
You can include an unescaped closing bracket by placing it right after the opening bracket, or right after the negating caret. [ ]x ] matches a closing bracket or an x. [ ^ ]x ] matches any character that is not a closing bracket or an x. This does not work in JavaScript , which treats [] as an empty character class that always fails to match, and [ ^ ] as a negated empty character class that matches any single character. Ruby treats empty character classes as an error. So both JavaScript and Ruby require closing brackets to be escaped with a backslash to include them as literals in a character class.
The hyphen can be included right after the opening bracket, or right before the closing bracket, or right after the negating caret. Both [ -x ] and [ x - ] match an x or a hyphen. [ ^ -x ] and [ ^ x - ] match any character thas is not an x or a hyphen. This works in all flavors discussed in this tutorial. Hyphens at other positions in character classes where they can't form a range may be interpreted as literals or as errors. Regex flavors are quite inconsistent about this.
Many regex tokens that work outside character classes can also be used inside character classes. This includes character escapes, octal escapes, and hexadecimal escapes for non-printable characters . For flavors that support Unicode , it also includes Unicode character escapes and Unicode properties. [ $ \u20AC ] matches a dollar or euro sign, assuming your regex flavor supports Unicode escapes.
If you repeat a character class by using the ? , * or + operators, you're repeating the entire character class. You're not repeating just the character that it matched. The regex [ 0 - 9 ] + can match 837 as well as 222 .
If you want to repeat the matched character, rather than the class, you need to use backreferences. ( [ 0 - 9 ] ) \1 + matches 222 but not 837 . When applied to the string 833337 , it matches 3333 in the middle of this string. If you do not want that, you need to use lookaround .
As was mentioned earlier: the order of the characters inside a character class does not matter. gr [ ae ] y matches grey in Is his hair grey or gray? , because that is the leftmost match . We already saw how the engine applies a regex consisting only of literal characters . Now we'll see how it applies a regex that has more than one permutation. That is: gr [ ae ] y can match both gray and grey .
Nothing noteworthy happens for the first twelve characters in the string. The engine fails to match g at every step, and continues with the next character in the string. When the engine arrives at the 13th character, g is matched. The engine then tries to match the remainder of the regex with the text. The next token in the regex is the literal r , which matches the next character in the text. So the third token, [ ae ] is attempted at the next character in the text ( e ). The character class gives the engine two options: match a or match e . It first attempts to match a , and fails.
But because we are using a regex-directed engine, it must continue trying to match all the other permutations of the regex pattern before deciding that the regex cannot be matched with the text starting at character 13. So it continues with the other option, and finds that e matches e . The last regex token is y , which can be matched with the following character as well. The engine has found a complete match with the text starting at character 13. It returns grey as the match result, and looks no further. Again, the leftmost match is returned, even though we put the a first in the character class, and gray could have been matched in the string. But the engine simply did not get that far, because another equally valid match was found to the left of it. gray is only matched if you tell the regex engine to continue looking for a second match in the remainder of the subject string after the first match.
Character class subtraction is supported by the XML Schema , XPath , .NET (version 2.0 and later), and JGsoft regex flavors. It makes it easy to match any single character present in one list (the character class), but not present in another list (the subtracted class). The syntax for this is [ class -[ subtract ] ] . If the character after a hyphen is an opening bracket, these flavors interpret the hyphen as the subtraction operator rather than the range operator. You can use the full character class syntax within the subtracted character class.
The character class [ a - z -[ aeiuo ] ] matches a single letter that is not a vowel. In other words: it matches a single consonant. Without character class subtraction or intersection , the only way to do this would be to list all consonants: [ b - d f - h j - n p - t v - z ] .
The character class [ \p{Nd} -[ ^ \p{IsThai} ] ] matches any single Thai digit. The base class matches any Unicode digit. All non-Thai characters are subtracted from that class. [ \p{Nd} -[ \P{IsThai} ] ] does the same. [ \p{IsThai} -[ ^ \p{Nd} ] ] and [ \p{IsThai} -[ \P{Nd} ] ] also match a single Thai digit by subtracting all non-digits from the Thai characters.
Since you can use the full character class syntax within the subtracted character class, you can subtract a class from the class being subtracted. [ 0 - 9 -[ 0 - 6 -[ 0 - 3 ] ] ] first subtracts 0-3 from 0-6 , yielding [ 0 - 9 -[ 4 - 6 ] ] , or [ 0 - 3 7 - 9 ] , which matches any character in the string 0123789 .
The class subtraction must always be the last element in the character class. [0-9-[4-6]a-f] is not a valid regular expression. It should be rewritten as [ 0 - 9 a - f -[ 4 - 6 ] ] . The subtraction works on the whole class. E.g. [ \p{Ll} \p{Lu} -[ \p{IsBasicLatin} ] ] matches all uppercase and lowercase Unicode letters, except any ASCII letters. The \p{IsBasicLatin} is subtracted from the combination of \p{Ll}\p{Lu} rather than from \p{Lu} alone. This regex will not match abc .
While you can use nested character class subtraction, you cannot subtract two classes sequentially. To subtract ASCII characters and Greek characters from a class with all Unicode letters, combine the ASCII and Greek characters into one class, and subtract that, as in [ \p{L} -[ \p{IsBasicLatin} \p{IsGreek} ] ] .
The character class [ ^ 1234 -[ 3456 ] ] is both negated and subtracted from. In all flavors that support character class subtraction, the base class is negated before it is subtracted from. This class should be read as "(not 1234) minus 3456". Thus this character class matches any character other than the digits 1, 2, 3, 4, 5, and 6.
Note that a regex like [ a - z -[aeiuo ] ] does not cause any errors in most regex flavors that do not support character class subtraction. But it won't match what you intended either. In most flavors, this regex consists of a character class followed by a literal ] . The character class matches a character that is either in the range a-z, or a hyphen, or an opening bracket, or a vowel. Since the a-z range and the vowels are redundant, you could write this character class as [ a - z -[ ] or [ -[ a - z ] in Perl. A hyphen after a range is treated as a literal character, just like a hyphen immediately after the opening bracket. This is true in the XML, .NET and JGsoft flavors too. [ a - z -_ ] matches a lowercase letter, a hyphen or an underscore in these flavors.
Strictly speaking, this means that the character class subtraction syntax is incompatible with Perl and the majority of other regex flavors. But in practice there's no difference. Using non-alphanumeric characters in character class ranges is very bad practice because it relies on the order of characters in the ASCII character table. That makes the regular expression hard to understand for the programmer who inherits your work. While [ A - [ ] would match any upper case letter or an opening square bracket in Perl, this regex is much clearer when written as [ A - Z [ ] . The former regex would cause an error with the XML, .NET and JGsoft flavors, because they interpret -[] as an empty subtracted class, leaving an unbalanced [ .
Character class intersection is supported by Java , JGsoft V2 , and by Ruby 1.9 and later. It makes it easy to match any single character that must be present in two sets of characters. The syntax for this is [ class &&[ intersect ] ] . You can use the full character class syntax within the intersected character class.
If the intersected class does not need a negating caret, then Java and Ruby allow you to omit the nested square brackets: [ class && intersect ] .
You cannot omit the nested square brackets in PowerGREP. If you do, PowerGREP interprets the ampersands as literals. So in PowerGREP [ class&&intersect ] is a character class containing only literals, just like [ clas&inter ] .
The character class [ a - z &&[ ^ aeiuo ] ] matches a single letter that is not a vowel. In other words: it matches a single consonant. Without character class subtraction or intersection, the only way to do this would be to list all consonants: [ b - d f - h j - n p - t v - z ] .
The character class [ \p{Nd} &&[ \p{IsThai} ] ] matches any single Thai digit. [ \p{IsThai} &&[ \p{Nd} ] ] does exactly the same.
You can intersect the same class more than once. [ 0 - 9 &&[ 0 - 6 &&[ 4 - 9 ] ] ] is the same as [ 4 - 6 ] as those are the only digits present in all three parts of the intersection. In Java and Ruby you can write the same regex as [ 0 - 9 &&[ 0 - 6 ] &&[ 4 - 9 ] ] , [ 0 - 9 &&[ 0 - 6 && 4 - 9 ] ] , [ 0 - 9 && 0 - 6 &&[ 4 - 9 ] ] , or just [ 0 - 9 && 0 - 6 && 4 - 9 ] . The nested square brackets are only needed if one of the parts of the intersection is negated.
If you do not use square brackets around the right hand part of the intersection, then there is no confusion that the entire remainder of the character class is the right hand part of the intersection. If you do use the square brackets, you could write something like [ 0 - 9&&[ 12] 56 ] . In Ruby, this is the same as [ 0 - 9 && 1256 ] . But Java has bugs that cause it to treat this as [ 0 - 9 && 56 ] , completely ignoring the nested brackets.
PowerGREP does not allow anything after the nested ] . The characters 56 in [ 0 - 9 &&[ 12 ] 56 ] are an error. This way there is no ambiguity about their meaning.
You also shouldn't put && at the very start or very end of the regex. Ruby treats [ 0 - 9 && ] and [ && 0 - 9 ] as intersections with an empty class, which matches no characters at all. Java ignores leading and trailing && operators. PowerGREP treats them as literal ampersands.
The character class [ ^ 1234 &&[ 3456 ] ] is both negated and intersected. In Java and PowerGREP, negation takes precedence over intersection. Java and PowerGREP read this regex as "(not 1234) and 3456". Thus in Java and PowerGREP this class is the same as [ 56 ] and matches the digits 5 and 6. In Ruby, intersection takes precedence over negation. Ruby reads [ ^ 1234 && 3456 ] as "not (1234 and 3456)". Thus in Ruby this class is the same as [ ^ 34 ] which matches anything except the digits 3 and 4.
If you want to negate the right hand side of the intersection, then you must use square brackets. Those automatically control precedence. So Java, PowerGREP, and Ruby all read [ 1234 &&[ ^ 3456 ] ] as "1234 and (not 3456)". Thus this regex is the same as [ 12 ] .
The ampersand has no special meaning in character classes in any other regular expression flavors discussed in this tutorial. The ampersand is simply a literal, and repeating it just adds needless duplicates. All these flavors treat [ 1234&&3456 ] as identical to [ &123456 ] .
Strictly speaking, this means that the character class intersection syntax is incompatible with the majority of other regex flavors. But in practice there's no difference, because there is no point in using two ampersands in a character class when you just want to add a literal ampersand. A single ampersand is still treated as a literal by Java, Ruby, and PowerGREP.
Since certain character classes are used often, a series of shorthand character classes are available. \d is short for [ 0 - 9 ] . In most flavors that support Unicode, \d includes all digits from all scripts. Notable exceptions are Java , JavaScript , and PCRE . These Unicode flavors match only ASCII digits with \d .
\w stands for "word character". It always matches the ASCII characters [ A - Z a - z 0 - 9 _ ] . Notice the inclusion of the underscore and digits. In most flavors that support Unicode, \w includes many characters from other scripts. There is a lot of inconsistency about which characters are actually included. Letters and digits from alphabetic scripts and ideographs are generally included. Connector punctuation other than the underscore and numeric symbols that aren't digits may or may not be included. XML Schema and XPath even include all symbols in \w . Again, Java , JavaScript , and PCRE match only ASCII characters with \w .
\s stands for "whitespace character". Again, which characters this actually includes, depends on the regex flavor. In all flavors discussed in this tutorial, it includes [ \t \r \n \f ] . That is: \s matches a space, a tab, a line break, or a form feed. Most flavors also include the vertical tab, with Perl (prior to version 5.18) and PCRE (prior to version 8.34) being notable exceptions. In flavors that support Unicode, \s normally includes all characters from the Unicode "separator" category. Java and PCRE are exceptions once again. But JavaScript does match all Unicode whitespace with \s .
Shorthand character classes can be used both inside and outside the square brackets. \s \d matches a whitespace character followed by a digit. [ \s \d ] matches a single character that is either whitespace or a digit. When applied to 1 + 2 = 3 , the former regex matches 2 (space two), while the latter matches 1 (one). [ \d a - f A - F ] matches a hexadecimal digit, and is equivalent to [ 0 - 9 a - f A - F ] if your flavor only matches ASCII characters with \d .
The above three shorthands also have negated versions. \D is the same as [ ^ \d ] , \W is short for [ ^ \w ] and \S is the equivalent of [ ^ \s ] .
Be careful when using the negated shorthands inside square brackets. [ \D \S ] is not the same as [ ^ \d \s ] . The latter matches any character that is neither a digit nor whitespace. It matches x , but not 8 . The former, however, matches any character that is either not a digit, or is not whitespace. Because all digits are not whitespace, and all whitespace characters are not digits, [ \D \S ] matches any character; digit, whitespace, or otherwise.
While support for \d , \s , and \w is quite universal, there are some regex flavors that support additional shorthand character classes. Perl 5.10 introduced \h and \v . \h matches horizontal whitespace, which includes the tab and all characters in the "space separator" Unicode category. It is the same as [ \t \p{Zs} ] . \v matches "vertical whitespace", which includes all characters treated as line breaks in the Unicode standard. It is the same as [ \n \cK \f \r \x85 \x{2028} \x{2029} ] .
PCRE also supports \h and \v starting with version 7.2. PHP does as of version 5.2.2, Java as of version 8, and the JGsoft engine as of version 2. Boost supports \h starting with version 1.42. No version of Boost supports \v as a shorthand.
In many other regex flavors, \v matches only the vertical tab character. Perl, PCRE, and PHP never supported this, so they were free to give \v a different meaning. Java 4 to 7 and JGsoft V1 did use \v to match only the vertical tab. Java 8 and JGsoft V2 changed the meaning of this token anyway. The vertical tab is also a vertical whitespace character. To avoid confusion, the above paragraph uses \cK to represent the vertical tab.
Ruby 1.9 and later have their own version of \h . It matches a single hexadecimal digit just like [ 0 - 9 a - f A - F ] . \v is a vertical tab in Ruby.
XML Schema , XPath , and JGsoft V2 regular expressions support four more shorthands that aren't supported by any other regular expression flavors. \i matches any character that may be the first character of an XML name. \c matches any character that may occur after the first character in an XML name. \I and \C are the respective negated shorthands. Note that the \c shorthand syntax conflicts with the control character syntax used in many other regex flavors.
You can use these four shorthands both inside and outside character classes using the bracket notation. They're very useful for validating XML references and values in your XML schemas. The regular expression \i \c * matches an XML name like xml:schema .
The regex < \i \c * \s * > matches an opening XML tag without any attributes. </ \i \c * \s * > matches any closing tag. < \i \c * ( \s + \i \c * \s * = \s * ( " [ ^ " ] * " | ' [ ^ ' ] * ' ) ) * \s * > matches an opening tag with any number of attributes. Putting it all together, < ( \i \c * ( \s + \i \c * \s * = \s * ( " [ ^ " ] * " | ' [ ^ ' ] * ' ) ) * | / \i \c * ) \s * > matches either an opening tag with attributes or a closing tag.
No other regex flavors discussed in this tutorial support XML character classes. If your XML files are plain ASCII , you can use
[
_:
A
-
Z
a
-
z
]
for
\i
and
[
-._:
A
-
Z
a
-
z
0
-
9
]
for
\c
. If you want to allow all Unicode characters that the XML standard allows, then you will end up with some pretty long regexes. You would have to use
[
:
A
-
Z
_
a
-
z
\u00C0
-
\u00D6
\u00D8
-
\u00F6
\u00F8
-
\u02FF
\u0370
-
\u037D
\u037F
-
\u1FFF
\u200C
-
\u200D
\u2070
-
\u218F
\u2C00
-
\u2FEF
\u3001
-
\uD7FF
\uF900
-
\uFDCF
\uFDF0
-
\uFFFD
]
instead of
\i
and
[
-.
0
-
9
:
A
-
Z
_
a
-
z
\u00B7
\u00C0
-
\u00D6
\u00D8
-
\u00F6
\u00F8
-
\u037D
\u037F
-
\u1FFF
\u200C
-
\u200D
\u203F
\u2040
\u2070
-
\u218F
\u2C00
-
\u2FEF
\u3001
-
\uD7FF
\uF900
-
\uFDCF
\uFDF0
-
\uFFFD
]
instead of
\c
.
In regular expressions, the dot or period is one of the most commonly used metacharacters . Unfortunately, it is also the most commonly misused metacharacter.
The dot matches a single character, without caring what that character is. The only exception are line break characters. In all regex flavors discussed in this tutorial, the dot does not match line breaks by default.
This exception exists mostly because of historic reasons. The first tools that used regular expressions were line-based. They would read a file line by line, and apply the regular expression separately to each line. The effect is that with these tools, the string could never contain line breaks, so the dot could never match them.
Modern tools and languages can apply regular expressions to very large strings or even entire files. Except for JavaScript and VBScript , all regex flavors discussed here have an option to make the dot match all characters, including line breaks.
In PowerGREP, tick the checkbox labeled "dot matches line breaks" to make the dot match all characters. In EditPad Pro, turn on the "Dot" or "Dot matches newline" search option.
In Perl, the mode where the dot also matches line breaks is called "single-line mode". This is a bit unfortunate, because it is easy to mix up this term with "multi-line mode". Multi-line mode only affects anchors , and single-line mode only affects the dot. You can activate single-line mode by adding an s after the regex code, like this: m/^regex$/s; .
Other languages and regex libraries have adopted Perl's terminology. When using the regex classes of the .NET framework , you activate this mode by specifying RegexOptions.Singleline , such as in Regex.Match("string", "regex", RegexOptions.Singleline) .
JavaScript and VBScript do not have an option to make the dot match line break characters. In those languages, you can use a character class such as [ \s \S ] to match any character. This character matches a character that is either a whitespace character (including line break characters), or a character that is not a whitespace character. Since all characters are either whitespace or non-whitespace, this character class matches any character.
In all of Boost 's regex grammars the dot matches line breaks by default. Boost's ECMAScript grammar allows you to turn this off with regex_constants::no_mod_m .
While support for the dot is universal among regex flavors, there are significant differences in which characters they treat as line break characters. All flavors treat the newline \n as a line break. UNIX text files terminate lines with a single newline. All the scripting languages discussed in this tutorial do not treat any other characters as line breaks. This isn't a problem even on Windows where text files normally break lines with a \r \n pair. That's because these scripting languages read and write files in text mode by default. When running on Windows, \r \n pairs are automatically converted into \n when a file is read, and \n is automatically written to file as \r \n .
std::regex , XML Schema and XPath also treat the carriage return \r as a line break character. JavaScript adds the Unicode line separator \u2028 and page separator \u2029 on top of that. Java includes these plus the Latin-1 next line control character \u0085 . Boost adds the form feed \f to the list. Only Delphi and the JGsoft flavor supports all Unicode line breaks, completing the mix with the vertical tab.
.NET is notably absent from the list of flavors that treat characters other than \n as line breaks. Unlike scripting languages that have their roots in the UNIX world, .NET is a Windows development framework that does not automatically strip carriage return characters from text files that it reads. If you read a Windows text file as a whole into a string, it will contain carriage returns. If you use the regex abc . * on that string, without setting RegexOptions.SingleLine, then it will match abc plus all characters that follow on the same line, plus the carriage return at the end of the line, but without the newline after that.
Some flavors allow you to control which characters should be treated as line breaks. Java has the UNIX_LINES option which makes it treat only \n as a line break. PCRE has options that allow you to choose between \n only, \r only, \r \n , or all Unicode line breaks.
On POSIX systems, the POSIX locale determines which characters are line breaks. The C locale treats only the newline \n as a line break. Unicode locales support all Unicode line breaks.
Perl 5.12 and PCRE 8.10 introduced \N which matches any single character that is not a line break, just like the dot does. Unlike the dot, \N is not affected by "single-line mode". \N . turns on single-line mode and then matches any character that is not a line break followed by any character regardless of whether it is a line break.
PCRE's options that control which characters are treated as line breaks affect \N in exactly the same way as they affect the dot.
PHP 5.3.4 and R 2.14.0 also support \N as their regex support is based on PCRE 8.10 or later. JGsoft V2 also supports \N .
The dot is a very powerful regex metacharacter. It allows you to be lazy. Put in a dot, and everything matches just fine when you test the regex on valid data. The problem is that the regex also matches in cases where it should not match. If you are new to regular expressions, some of these cases may not be so obvious at first.
Let's illustrate this with a simple example. Say we want to match a date in mm/dd/yy format, but we want to leave the user the choice of date separators. The quick solution is \d \d . \d \d . \d \d . Seems fine at first. It matches a date like 02/12/03 just fine. Trouble is: 02512703 is also considered a valid date by this regular expression. In this match, the first dot matched 5 , and the second matched 7 . Obviously not what we intended.
\d \d [ - /. ] \d \d [ - /. ] \d \d is a better solution. This regex allows a dash, space, dot and forward slash as date separators. Remember that the dot is not a metacharacter inside a character class , so we do not need to escape it with a backslash.
This regex is still far from perfect. It matches 99/99/99 as a valid date. [ 01 ] \d [ - /. ] [ 0 - 3 ] \d [ - /. ] \d \d is a step ahead, though it still matches 19/39/99 . How perfect you want your regex to be depends on what you want to do with it. If you are validating user input, it has to be perfect. If you are parsing data files from a known source that generates its files in the same way every time, our last attempt is probably more than sufficient to parse the data without errors. You can find a better regex to match dates in the example section.
A negated character class is often more appropriate than the dot. The tutorial section that explains the repeat operators star and plus covers this in more detail. But the warning is important enough to mention it here as well. Again let's illustrate with an example.
Suppose you want to match a double-quoted string. Sounds easy. We can have any number of any character between the double quotes, so " . * " seems to do the trick just fine. The dot matches any character, and the star allows the dot to be repeated any number of times, including zero. If you test this regex on Put a "string" between double quotes , it matches "string" just fine. Now go ahead and test it on Houston, we have a problem with "string one" and "string two". Please respond.
Ouch. The regex matches "string one" and "string two" . Definitely not what we intended. The reason for this is that the star is greedy .
In the date-matching example, we improved our regex by replacing the dot with a character class. Here, we do the same with a negated character class. Our original definition of a double-quoted string was faulty. We do not want any number of any character between the quotes. We want any number of characters that are not double quotes or newlines between the quotes. So the proper regex is " [ ^ " \r \n ] * " .
Thus far, we have learned about literal characters , character classes , and the dot . Putting one of these in a regex tells the regex engine to try to match a single character.
Anchors are a different breed. They do not match any character at all. Instead, they match a position before, after, or between characters. They can be used to "anchor" the regex match at a certain position. The caret ^ matches the position before the first character in the string. Applying ^ a to abc matches a . ^ b does not match abc at all, because the b cannot be matched right after the start of the string, matched by ^ . See below for the inside view of the regex engine.
Similarly, $ matches right after the last character in the string. c $ matches c in abc , while a $ does not match at all.
A regex that consists solely of an anchor can only find zero-length matches . This can be useful, but can also create complications that are explained near the end of this tutorial.
When using regular expressions in a programming language to validate user input, using anchors is very important. If you use the code if ($input =~ m/\d+/) in a Perl script to see if the user entered an integer number, it will accept the input even if the user entered qsdf4ghjk , because \d + matches the 4 . The correct regex to use is ^ \d + $ . Because "start of string" must be matched before the match of \d + , and "end of string" must be matched right after it, the entire string must consist of digits for ^ \d + $ to be able to match.
It is easy for the user to accidentally type in a space. When Perl reads from a line from a text file, the line break is also be stored in the variable. So before validating input, it is good practice to trim leading and trailing whitespace . ^ \s + matches leading whitespace and \s + $ matches trailing whitespace. In Perl, you could use $input =~ s/^\s+|\s+$//g . Handy use of alternation and /g allows us to do this in a single line of code.
If you have a string consisting of multiple lines, like first line\nsecond line (where \n indicates a line break), it is often desirable to work with lines, rather than the entire string. Therefore, most regex engines discussed in this tutorial have the option to expand the meaning of both anchors. ^ can then match at the start of the string (before the f in the above string), as well as after each line break (between \n and s ). Likewise, $ still matches at the end of the string (after the last e ), and also before every line break (between e and \n ).
In text editors like EditPad Pro or GNU Emacs, and regex tools like PowerGREP , the caret and dollar always match at the start and end of each line. This makes sense because those applications are designed to work with entire files, rather than short strings. In Ruby and std::regex the caret and dollar also always match at the start and end of each line. In Boost they match at the start and end of each line by default. Boost allows you to turn this off with regex_constants::no_mod_m when using the ECMAScript grammar.
In all other programming languages and libraries discussed on this website , you have to explicitly activate this extended functionality. It is traditionally called "multi-line mode". In Perl, you do this by adding an m after the regex code, like this: m/^regex$/m; . In .NET , the anchors match before and after newlines when you specify RegexOptions.Multiline , such as in Regex.Match("string", "regex", RegexOptions.Multiline) .
The tutorial page about the dot already discussed which characters are seen as line break characters by the various regex flavors. This affects the anchors just as much when in multi-line mode, and when the dollar matches before the end of the final break. The anchors handle line breaks that consist of a single character the same way as the dot in each regex flavor.
For anchors there's an additional consideration when CR and LF occur as a pair and the regex flavor treats both these characters as line breaks. Delphi , Java , and the JGsoft flavor treat CRLF as an indivisible pair. ^ matches after CRLF and $ matches before CRLF, but neither match in the middle of a CRLF pair. JavaScript and XPath treat CRLF pairs as two line breaks. ^ matches in the middle of and after CRLF, while $ matches before and in the middle of CRLF.
\A only ever matches at the start of the string. Likewise, \Z only ever matches at the end of the string. These two tokens never match at line breaks. This is true in all regex flavors discussed in this tutorial, even when you turn on "multiline mode". In EditPad Pro and PowerGREP, where the caret and dollar always match at the start and end of lines, \A and \Z only match at the start and the end of the entire file.
JavaScript , POSIX , XML , and XPath do not support \A and \Z . You're stuck with using the caret and dollar for this purpose.
The GNU extensions to POSIX regular expressions use \` (backtick) to match the start of the string, and \' (single quote) to match the end of the string.
Because Perl returns a string with a newline at the end when reading a line from a file, Perl's regex engine matches $ at the position before the line break at the end of the string even when multi-line mode is turned off. Perl also matches $ at the very end of the string, regardless of whether that character is a line break. So ^ \d + $ matches 123 whether the subject string is 123 or 123\n .
Most modern regex flavors have copied this behavior. That includes .NET , Java , PCRE , Delphi , PHP , and Python . This behavior is independent of any settings such as "multi-line mode".
In all these flavors except Python , \Z also matches before the final line break. If you only want a match at the absolute very end of the string, use \z (lower case z instead of upper case Z). \A \d + \z does not match 123\n . \z matches after the line break, which is not matched by the shorthand character class .
In Python, \Z matches only at the very end of the string. Python does not support \z .
If a string ends with multiple line breaks and multi-line mode is off then $ only matches before the last of those line breaks in all flavors where it can match before the final break. The same is true for \Z regardless of multi-line mode.
Boost is the only exception. In Boost, \Z can match before any number of trailing line breaks as well as at the very end of the string. So if the subject string ends with three line breaks, Boost's \Z has four positions that it can match at. Like in all other flavors, Boost's \Z is independent of multi-line mode. Boost's $ only matches at the very end of the string when you turn off multi-line mode (which is on by default in Boost).
Let's see what happens when we try to match ^ 4 $ to 749\n486\n4 (where \n represents a newline character) in multi-line mode. As usual, the regex engine starts at the first character: 7 . The first token in the regular expression is ^ . Since this token is a zero-length token, the engine does not try to match it with the character, but rather with the position before the character that the regex engine has reached so far. ^ indeed matches the position before 7 . The engine then advances to the next regex token: 4 . Since the previous token was zero-length, the regex engine does not advance to the next character in the string. It remains at 7 . 4 is a literal character, which does not match 7 . There are no other permutations of the regex, so the engine starts again with the first regex token, at the next character: 4 . This time, ^ cannot match at the position before the 4. This position is preceded by a character, and that character is not a newline. The engine continues at 9 , and fails again. The next attempt, at \n , also fails. Again, the position before \n is preceded by a character, 9 , and that character is not a newline.
Then, the regex engine arrives at the second 4 in the string. The ^ can match at the position before the 4 , because it is preceded by a newline character. Again, the regex engine advances to the next regex token, 4 , but does not advance the character position in the string. 4 matches 4 , and the engine advances both the regex token and the string character. Now the engine attempts to match $ at the position before (indeed: before) the 8 . The dollar cannot match here, because this position is followed by a character, and that character is not a newline.
Yet again, the engine must try to match the first token again. Previously, it was successfully matched at the second 4 , so the engine continues at the next character, 8 , where the caret does not match. Same at the six and the newline.
Finally, the regex engine tries to match the first token at the third 4 in the string. With success. After that, the engine successfully matches 4 with 4 . The current regex token is advanced to $ , and the current character is advanced to the very last position in the string: the void after the string. No regex token that needs a character to match can match here. Not even a negated character class . However, we are trying to match a dollar sign, and the mighty dollar is a strange beast. It is zero-length, so it tries to match the position before the current character. It does not matter that this "character" is the void after the string. In fact, the dollar checks the current character. It must be either a newline, or the void after the string, for $ to match the position before the current character. Since that is the case after the example, the dollar matches successfully.
Since $ was the last token in the regex, the engine has found a successful match: the last 4 in the string.
The metacharacter \b is an anchor like the caret and the dollar sign. It matches at a position that is called a "word boundary". This match is zero-length.
There are three different positions that qualify as word boundaries:
Simply put: \b allows you to perform a "whole words only" search using a regular expression in the form of \b word \b . A "word character" is a character that can be used to form words. All characters that are not "word characters" are "non-word characters".
Exactly which characters are word characters depends on the regex flavor you're working with. In most flavors, characters that are matched by the short-hand character class \w are the characters that are treated as word characters by word boundaries. Java is an exception. Java supports Unicode for \b but not for \w .
Most flavors, except the ones discussed below, have only one metacharacter that matches both before a word and after a word. This is because any position between characters can never be both at the start and at the end of a word. Using only one operator makes things easier for you.
Since digits are considered to be word characters, \b 4 \b can be used to match a 4 that is not part of a larger number. This regex does not match 44 sheets of a4 . So saying " \b matches before and after an alphanumeric sequence" is more exact than saying "before and after a word".
\B is the negated version of \b . \B matches at every position where \b does not. Effectively, \B matches at any position between two word characters as well as at any position between two non-word characters.
Let's see what happens when we apply the regex \b is \b to the string This island is beautiful . The engine starts with the first token \b at the first character T . Since this token is zero-length, the position before the character is inspected. \b matches here, because the T is a word character and the character before it is the void before the start of the string. The engine continues with the next token: the literal i . The engine does not advance to the next character in the string, because the previous regex token was zero-length. i does not match T , so the engine retries the first token at the next character position.
\b cannot match at the position between the T and the h . It cannot match between the h and the i either, and neither between the i and the s .
The next character in the string is a space. \b matches here because the space is not a word character, and the preceding character is. Again, the engine continues with the i which does not match with the space.
Advancing a character and restarting with the first regex token, \b matches between the space and the second i in the string. Continuing, the regex engine finds that i matches i and s matches s . Now, the engine tries to match the second \b at the position before the l . This fails because this position is between two word characters. The engine reverts to the start of the regex and advances one character to the s in island . Again, the \b fails to match and continues to do so until the second space is reached. It matches there, but matching the i fails.
But \b matches at the position before the third i in the string. The engine continues, and finds that i matches i and s matches s . The last token in the regex, \b , also matches at the position before the third space in the string because the space is not a word character, and the character before it is.
The engine has successfully matched the word is in our string, skipping the two earlier occurrences of the characters i and s. If we had used the regular expression is , it would have matched the is in This .
Word boundaries, as described above, are supported by most regular expression flavors. Notable exceptions are the POSIX and XML Schema flavors, which don't support word boundaries at all. Tcl uses a different syntax.
In Tcl, \b matches a backspace character, just like \x08 in most regex flavors (including Tcl's). \B matches a single backslash character in Tcl, just like \\ in all other regex flavors (and Tcl too).
Tcl uses the letter "y" instead of the letter "b" to match word boundaries. \y matches at any word boundary position, while \Y matches at any position that is not a word boundary. These Tcl regex tokens match exactly the same as \b and \B in Perl-style regex flavors. They don't discriminate between the start and the end of a word.
Tcl has two more word boundary tokens that do discriminate between the start and end of a word. \m matches only at the start of a word. That is, it matches at any position that has a non-word character to the left of it, and a word character to the right of it. It also matches at the start of the string if the first character in the string is a word character. \M matches only at the end of a word. It matches at any position that has a word character to the left of it, and a non-word character to the right of it. It also matches at the end of the string if the last character in the string is a word character.
The only regex engine that supports Tcl-style word boundaries (besides Tcl itself) is the JGsoft engine . In PowerGREP and EditPad Pro , \b and \B are Perl-style word boundaries, while \y , \Y , \m and \M are Tcl-style word boundaries.
In most situations, the lack of \m and \M tokens is not a problem. \y word \y finds "whole words only" occurrences of "word" just like \m word \M would. \M word \m could never match anywhere, since \M never matches at a position followed by a word character, and \m never at a position preceded by one. If your regular expression needs to match characters before or after \y , you can easily specify in the regex whether these characters should be word characters or non-word characters. If you want to match any word, \y \w + \y gives the same result as \m . + \M . Using \w instead of the dot automatically restricts the first \y to the start of a word, and the second \y to the end of a word. Note that \y . + \y would not work. This regex matches each word, and also each sequence of non-word characters between the words in your subject string. That said, if your flavor supports \m and \M , the regex engine could apply \m \w + \M slightly faster than \y \w + \y , depending on its internal optimizations.
If your regex flavor supports lookahead and lookbehind , you can use (?<! \w ) (?= \w ) to emulate Tcl's \m and (?<= \w ) (?! \w ) to emulate \M . Though quite a bit more verbose, these lookaround constructs match exactly the same as Tcl's word boundaries.
If your flavor has lookahead but not lookbehind, and also has Perl-style word boundaries, you can use \b (?= \w ) to emulate Tcl's \m and \b (?! \w ) to emulate \M . \b matches at the start or end of a word, and the lookahead checks if the next character is part of a word or not. If it is we're at the start of a word. Otherwise, we're at the end of a word.
The GNU extensions to POSIX regular expressions add support for the \b and \B word boundaries, as described above. GNU also uses its own syntax for start-of-word and end-of-word boundaries. \< matches at the start of a word, like Tcl's \m . \> matches at the end of a word, like Tcl's \M .
Boost also treats \< and \> as word boundaries when using the ECMAScript, extended, egrep, or awk grammar.
The POSIX standard defines [[:<:]] as a start-of-word boundary, and [[:>:]] as an end-of-word boundary. Though the syntax is borrowed from POSIX bracket expressions , these tokens are word boundaries that have nothing to do with and cannot be used inside character classes. Tcl and GNU also support POSIX word boundaries. PCRE supports POSIX word boundaries starting with version 8.34. Boost supports them in all its grammars.
I already explained how you can use character classes to match a single character out of several possible characters. Alternation is similar. You can use alternation to match a single regular expression out of several possible regular expressions.
If you want to search for the literal text cat or dog , separate both options with a vertical bar or pipe symbol: cat | dog . If you want more options, simply expand the list: cat | dog | mouse | fish .
The alternation operator has the lowest precedence of all regex operators. That is, it tells the regex engine to match either everything to the left of the vertical bar, or everything to the right of the vertical bar. If you want to limit the reach of the alternation, you need to use parentheses for grouping. If we want to improve the first example to match whole words only, we would need to use \b ( cat | dog ) \b . This tells the regex engine to find a word boundary , then either cat or dog , and then another word boundary. If we had omitted the parentheses then the regex engine would have searched for a word boundary followed by cat , or, dog followed by a word boundary.
I already explained that the regex engine is eager . It stops searching as soon as it finds a valid match. The consequence is that in certain situations, the order of the alternatives matters. Suppose you want to use a regex to match a list of function names in a programming language: Get, GetValue, Set or SetValue. The obvious solution is Get | GetValue | Set | SetValue . Let's see how this works out when the string is SetValue .
The regex engine starts at the first token in the regex, G , and at the first character in the string, S . The match fails. However, the regex engine studied the entire regular expression before starting. So it knows that this regular expression uses alternation, and that the entire regex has not failed yet. So it continues with the second option, being the second G in the regex. The match fails again. The next token is the first S in the regex. The match succeeds, and the engine continues with the next character in the string, as well as the next token in the regex. The next token in the regex is the e after the S that just successfully matched. e matches e . The next token, t matches t .
At this point, the third option in the alternation has been successfully matched. Because the regex engine is eager, it considers the entire alternation to have been successfully matched as soon as one of the options has. In this example, there are no other tokens in the regex outside the alternation, so the entire regex has successfully matched Set in SetValue .
Contrary to what we intended, the regex did not match the entire string. There are several solutions. One option is to take into account that the regex engine is eager, and change the order of the options. If we use GetValue | Get | SetValue | Set , SetValue is attempted before Set , and the engine matches the entire string. We could also combine the four options into two and use the question mark to make part of them optional: Get ( Value ) ? | Set ( Value ) ? . Because the question mark is greedy, SetValue is be attempted before Set .
The best option is probably to express the fact that we only want to match complete words. We do not want to match Set or SetValue if the string is SetValueFunction . So the solution is \b ( Get | GetValue | Set | SetValue ) \b or \b ( Get ( Value ) ? | Set ( Value ) ? ) \b . Since all options have the same end, we can optimize this further to \b ( Get | Set ) ( Value ) ? \b .
Alternation is where regex-directed and text-directed engines differ . When a text-directed engine attempts Get | GetValue | Set | SetValue on SetValue , it tries all permutations of the regex at the start of the string. It does so efficiently, without any backtracking. It sees that the regex can find a match at the start of the string, and that the matched text can be either Set or SetValue . Because the text-directed engine evaluates the regex as a whole, it has no concept of one alternative being listed before another. But it has to make a choice as to which match to return. It always returns the longest match, in this case SetValue .
The POSIX standard leaves it up to the implementation to choose a text-directed or regex-directed engine. A BRE that includes backreferences needs to be evaluated using a regex-directed engine. But a BRE without backreferences or an ERE can be evaluated using a text-directed engine. But the POSIX standard does mandate that the longest match be returned, even when a regex-directed engine is used. Such an engine cannot be eager. It has to continue trying all alternatives even after a match is found, in order to find the longest one. This can result in very poor performance when a regex contains multiple quantifiers or a combination of quantifiers and alternation, as all combinations have to be tried to find the longest match.
The Tcl and GNU flavors also work this way.
The question mark makes the preceding token in the regular expression optional. colo u ? r matches both colour and color . The question mark is called a quantifier.
You can make several tokens optional by grouping them together using parentheses, and placing the question mark after the closing parenthesis. E.g.: Nov ( ember ) ? matches Nov and November .
You can write a regular expression that matches many alternatives by including more than one question mark. Feb ( ruary ) ? 23 ( rd ) ? matches February 23rd , February 23 , Feb 23rd and Feb 23 .
You can also use curly braces to make something optional. colo u {0,1} r is the same as colo u ? r . POSIX BRE and GNU BRE do not support either syntax. These flavors require backslashes to give curly braces their special meaning: colo u \{0,1\} r .
The question mark is the first metacharacter introduced by this tutorial that is greedy . The question mark gives the regex engine two choices: try to match the part the question mark applies to, or do not try to match it. The engine always tries to match that part. Only if this causes the entire regular expression to fail, will the engine try ignoring the part the question mark applies to.
The effect is that if you apply the regex Feb 23 ( rd ) ? to the string Today is Feb 23rd, 2003 , the match is always Feb 23rd and not Feb 23 . You can make the question mark lazy (i.e. turn off the greediness) by putting a second question mark after the first.
The discussion about the other repetition operators has more details on greedy and lazy quantifiers.
Let's apply the regular expression colo u ? r to the string The colonel likes the color green .
The first token in the regex is the literal c . The first position where it matches successfully is the c in colonel . The engine continues, and finds that o matches o , l matches l and another o matches o . Then the engine checks whether u matches n . This fails. However, the question mark tells the regex engine that failing to match u is acceptable. Therefore, the engine skips ahead to the next regex token: r . But this fails to match n as well. Now, the engine can only conclude that the entire regular expression cannot be matched starting at the c in colonel . Therefore, the engine starts again trying to match c to the first o in colonel .
After a series of failures, c matches the c in color , and o , l and o match the following characters. Now the engine checks whether u matches r . This fails. Again: no problem. The question mark allows the engine to continue with r . This matches r and the engine reports that the regex successfully matched color in our string.
One repetition operator or quantifier was already introduced: the question mark . It tells the engine to attempt to match the preceding token zero times or once, in effect making it optional.
The asterisk or star tells the engine to attempt to match the preceding token zero or more times. The plus tells the engine to attempt to match the preceding token once or more. < [ A - Z a - z ] [ A - Z a - z 0 - 9 ] * > matches an HTML tag without any attributes. The angle brackets are literals . The first character class matches a letter. The second character class matches a letter or digit. The star repeats the second character class. Because we used the star, it's OK if the second character class matches nothing. So our regex will match a tag like <B> . When matching <HTML> , the first character class will match H . The star will cause the second character class to be repeated three times, matching T , M and L with each step.
I could also have used < [ A - Z a - z 0 - 9 ] + > . I did not, because this regex would match <1> , which is not a valid HTML tag. But this regex may be sufficient if you know the string you are searching through does not contain any such invalid tags.
There's an additional quantifier that allows you to specify how many times a token can be repeated. The syntax is { min , max } , where min is zero or a positive integer number indicating the minimum number of matches, and max is an integer equal to or greater than min indicating the maximum number of matches. If the comma is present but max is omitted, the maximum number of matches is infinite. So {0,1} is the same as ? , {0,} is the same as * , and {1,} is the same as + . Omitting both the comma and max tells the engine to repeat the token exactly min times.
You could use \b [ 1 - 9 ] [ 0 - 9 ] {3} \b to match a number between 1000 and 9999. \b [ 1 - 9 ] [ 0 - 9 ] {2,4} \b matches a number between 100 and 99999. Notice the use of the word boundaries .
Suppose you want to use a regex to match an HTML tag. You know that the input will be a valid HTML file, so the regular expression does not need to exclude any invalid use of sharp brackets. If it sits between sharp brackets, it is an HTML tag.
Most people new to regular expressions will attempt to use < . + > . They will be surprised when they test it on a string like This is a <EM>first</EM> test . You might expect the regex to match <EM> and when continuing after that match, </EM> .
But it does not. The regex will match <EM>first</EM> . Obviously not what we wanted. The reason is that the plus is greedy . That is, the plus causes the regex engine to repeat the preceding token as often as possible. Only if that causes the entire regex to fail, will the regex engine backtrack . That is, it will go back to the plus, make it give up the last iteration, and proceed with the remainder of the regex. Let's take a look inside the regex engine to see in detail how this works and why this causes our regex to fail. After that, I will present you with two possible solutions.
Like the plus, the star and the repetition using curly braces are greedy.
The first token in the regex is < . This is a literal . As we already know, the first place where it will match is the first < in the string. The next token is the dot, which matches any character except newlines. The dot is repeated by the plus. The plus is greedy . Therefore, the engine will repeat the dot as many times as it can. The dot matches E , so the regex continues to try to match the dot with the next character. M is matched, and the dot is repeated once more. The next character is the > . You should see the problem by now. The dot matches the > , and the engine continues repeating the dot. The dot will match all remaining characters in the string. The dot fails when the engine has reached the void after the end of the string. Only at this point does the regex engine continue with the next token: > .
So far, < . + has matched <EM>first</EM> test and the engine has arrived at the end of the string. > cannot match here. The engine remembers that the plus has repeated the dot more often than is required. (Remember that the plus requires the dot to match only once.) Rather than admitting failure, the engine will backtrack . It will reduce the repetition of the plus by one, and then continue trying the remainder of the regex.
So the match of . + is reduced to EM>first</EM> tes . The next token in the regex is still > . But now the next character in the string is the last t . Again, these cannot match, causing the engine to backtrack further. The total match so far is reduced to <EM>first</EM> te . But > still cannot match. So the engine continues backtracking until the match of . + is reduced to EM>first</EM . Now, > can match the next character in the string. The last token in the regex has been matched. The engine reports that <EM>first</EM> has been successfully matched.
Remember that the regex engine is eager to return a match. It will not continue backtracking further to see if there is another possible match. It will report the first valid match it finds. Because of greediness, this is the leftmost longest match.
The quick fix to this problem is to make the plus lazy instead of greedy. Lazy quantifiers are sometimes also called "ungreedy" or "reluctant". You can do that by putting a question mark after the plus in the regex. You can do the same with the star, the curly braces and the question mark itself. So our example becomes < . + ? > . Let's have another look inside the regex engine.
Again, < matches the first < in the string. The next token is the dot, this time repeated by a lazy plus. This tells the regex engine to repeat the dot as few times as possible. The minimum is one. So the engine matches the dot with E . The requirement has been met, and the engine continues with > and M . This fails. Again, the engine will backtrack . But this time, the backtracking will force the lazy plus to expand rather than reduce its reach. So the match of . + is expanded to EM , and the engine tries again to continue with > . Now, > is matched successfully. The last token in the regex has been matched. The engine reports that <EM> has been successfully matched. That's more like it.
In this case, there is a better option than making the plus lazy. We can use a greedy plus and a negated character class : < [ ^ > ] + > . The reason why this is better is because of the backtracking. When using the lazy plus, the engine has to backtrack for each character in the HTML tag that it is trying to match. When using the negated character class, no backtracking occurs at all when the string contains valid HTML code. Backtracking slows down the regex engine. You will not notice the difference when doing a single search in a text editor. But you will save plenty of CPU cycles when using such a regex repeatedly in a tight loop in a script that you are writing, or perhaps in a custom syntax coloring scheme for EditPad Pro .
Only regex-directed engines backtrack. Text-directed engines don't and thus do not get the speed penalty. But they also do not support lazy quantifiers.
The \Q…\E sequence escapes a string of characters, matching them as literal characters. The escaped characters are treated as individual characters. If you place a quantifier after the \E , it will only be applied to the last character. E.g. if you apply *\d+* + to *\d+**\d+* , the match will be *\d+** . Only the asterisk is repeated. Java 4 and 5 have a bug that causes the whole \Q…E sequence to be repeated, yielding the whole subject string as the match. This was fixed in Java 6.
By placing part of a regular expression inside round brackets or parentheses, you can group that part of the regular expression together. This allows you to apply a quantifier to the entire group or to restrict alternation to part of the regex.
Only parentheses can be used for grouping. Square brackets define a character class , and curly braces are used by a quantifier with specific limits .
Besides grouping part of a regular expression together, parentheses also create a numbered capturing group. It stores the part of the string matched by the part of the regular expression inside the parentheses.
The regex Set ( Value ) ? matches Set or SetValue . In the first case, the first (and only) capturing group remains empty. In the second case, the first capturing group matches Value .
If you do not need the group to capture its match, you can optimize this regular expression into Set (?: Value ) ? . The question mark and the colon after the opening parenthesis are the syntax that creates a non-capturing group. The question mark after the opening bracket is unrelated to the question mark at the end of the regex. The final question mark is the quantifier that makes the previous token optional . This quantifier cannot appear after an opening parenthesis, because there is nothing to be made optional at the start of a group. Therefore, there is no ambiguity between the question mark as an operator to make a token optional and the question mark as part of the syntax for non-capturing groups, even though this may be confusing at first. There are other kinds of groups that use the (? syntax in combination with other characters than the colon that are explained later in this tutorial.
color= (?: red | green | blue ) is another regex with a non-capturing group. This regex has no quantifiers.
Regex flavors that support named capture often have an option to turn all unnamed groups into non-capturing groups .
Capturing groups make it easy to extract part of the regex match. You can reuse the text inside the regular expression via a backreference . Backreferences can also be used in replacement strings. Please check the replacement text tutorial for details.
Backreferences match the same text as previously matched by a capturing group. Suppose you want to match a pair of opening and closing HTML tags, and the text in between. By putting the opening tag into a backreference, we can reuse the name of the tag for the closing tag. Here's how: < ( [ A - Z ] [ A - Z 0 - 9 ] * ) \b [ ^ > ] * > . * ? </ \1 > . This regex contains only one pair of parentheses, which capture the string matched by [ A - Z ] [ A - Z 0 - 9 ] * . This is the opening HTML tag. (Since HTML tags are case insensitive, this regex requires case insensitive matching.) The backreference \1 (backslash one) references the first capturing group. \1 matches the exact same text that was matched by the first capturing group. The / before it is a literal character. It is simply the forward slash in the closing HTML tag that we are trying to match.
To figure out the number of a particular backreference, scan the regular expression from left to right. Count the opening parentheses of all the numbered capturing groups. The first parenthesis starts backreference number one, the second number two, etc. Skip parentheses that are part of other syntax such as non-capturing groups. This means that non-capturing parentheses have another benefit: you can insert them into a regular expression without changing the numbers assigned to the backreferences. This can be very useful when modifying a complex regular expression.
You can reuse the same backreference more than once. ( [ a - c ] ) x \1 x \1 matches axaxa , bxbxb and cxcxc .
Most regex flavors support up to 99 capturing groups and double-digit backreferences. So \99 is a valid backreference if your regex has 99 capturing groups.
Let's see how the regex engine applies the regex < ( [ A - Z ] [ A - Z 0 - 9 ] * ) \b [ ^ > ] * > . * ? </ \1 > to the string Testing <B><I>bold italic</I></B> text . The first token in the regex is the literal < . The regex engine traverses the string until it can match at the first < in the string. The next token is [ A - Z ] . The regex engine also takes note that it is now inside the first pair of capturing parentheses. [ A - Z ] matches B . The engine advances to [ A - Z 0 - 9 ] and > . This match fails. However, because of the star , that's perfectly fine. The position in the string remains at > . The word boundary \b matches at the > because it is preceded by B . The word boundary does not make the engine advance through the string. The position in the regex is advanced to [ ^ > ] .
This step crosses the closing bracket of the first pair of capturing parentheses. This prompts the regex engine to store what was matched inside them into the first backreference. In this case, B is stored.
After storing the backreference, the engine proceeds with the match attempt. [ ^ > ] does not match > . Again, because of another star, this is not a problem. The position in the string remains at > , and position in the regex is advanced to > . These obviously match. The next token is a dot, repeated by a lazy star. Because of the laziness, the regex engine initially skips this token, taking note that it should backtrack in case the remainder of the regex fails.
The engine has now arrived at the second < in the regex, and the second < in the string. These match. The next token is / . This does not match I , and the engine is forced to backtrack to the dot. The dot matches the second < in the string. The star is still lazy, so the engine again takes note of the available backtracking position and advances to < and I . These do not match, so the engine again backtracks.
The backtracking continues until the dot has consumed <I>bold italic . At this point, < matches the third < in the string, and the next token is / which matches / . The next token is \1 . Note that the token is the backreference, and not B . The engine does not substitute the backreference in the regular expression. Every time the engine arrives at the backreference, it reads the value that was stored. This means that if the engine had backtracked beyond the first pair of capturing parentheses before arriving the second time at \1 , the new value stored in the first backreference would be used. But this did not happen here, so B it is. This fails to match at I , so the engine backtracks again, and the dot consumes the third < in the string.
Backtracking continues again until the dot has consumed <I>bold italic</I> . At this point, < matches < and / matches / . The engine arrives again at \1 . The backreference still holds B . \1 matches B . The last token in the regex, > matches > . A complete match has been found: <B><I>bold italic</I></B> .
You may have wondered about the word boundary \b in the < ( [ A - Z ] [ A - Z 0 - 9 ] * ) \b [ ^ > ] * > . * ? </ \1 > mentioned above. This is to make sure the regex won't match incorrectly paired tags such as <boo> bold</b> . You may think that cannot happen because the capturing group matches boo which causes \1 to try to match the same, and fail. That is indeed what happens. But then the regex engine backtracks.
Let's take the regex < ( [ A - Z ] [ A - Z 0 - 9 ] * ) [ ^ > ] * > . * ? </ \1 > without the word boundary and look inside the regex engine at the point where \1 fails the first time. First, . * ? continues to expand until it has reached the end of the string, and </ \1 > has failed to match each time . * ? matched one more character.
Then the regex engine backtracks into the capturing group. [ A - Z 0 - 9 ] * has matched oo , but would just as happily match o or nothing at all. When backtracking, [ A - Z 0 - 9 ] * is forced to give up one character. The regex engine continues, exiting the capturing group a second time. Since [A-Z][A-Z0-9]* has now matched bo , that is what is stored into the capturing group, overwriting boo that was stored before. [ ^ > ] * matches the second o in the opening tag. > . * ? </ matches >bold< . \1 fails again.
The regex engine does all the same backtracking once more, until [ A - Z 0 - 9 ] * is forced to give up another character, causing it to match nothing, which the star allows. The capturing group now stores just b . [ ^ > ] * now matches oo . > . * ? </ once again matches >bold< . \1 now succeeds, as does > and an overall match is found. But not the one we wanted.
There are several solutions to this. One is to use the word boundary. When [ A - Z 0 - 9 ] * backtracks the first time, reducing the capturing group to bo , \b fails to match between o and o . This forces [ A - Z 0 - 9 ] * to backtrack again immediately. The capturing group is reduced to b and the word boundary fails between b and o . There are no further backtracking positions, so the whole match attempt fails.
The reason we need the word boundary is that we're using [ ^ > ] * to skip over any attributes in the tag. If your paired tags never have any attributes, you can leave that out, and use < ( [ A - Z ] [ A - Z 0 - 9 ] * ) > . * ? </ \1 > . Each time [ A - Z 0 - 9 ] * backtracks, the > that follows it fails to match, quickly ending the match attempt.
If you don't want the regex engine to backtrack into capturing groups, you can use an atomic group. The tutorial section on atomic grouping has all the details.
As I mentioned in the above inside look, the regex engine does not permanently substitute backreferences in the regular expression. It will use the last match saved into the backreference each time it needs to be used. If a new match is found by capturing parentheses, the previously saved match is overwritten. There is a clear difference between ( [ abc ] + ) and ( [ abc ] ) + . Though both successfully match cab , the first regex will put cab into the first backreference, while the second regex will only store b . That is because in the second regex, the plus caused the pair of parentheses to repeat three times. The first time, c was stored. The second time, a , and the third time b . Each time, the previous value was overwritten, so b remains.
This also means that ( [ abc ] + ) = \1 will match cab=cab , and that ( [ abc ] ) + = \1 will not. The reason is that when the engine arrives at \1 , it holds b which fails to match c . Obvious when you look at a simple example like this one, but a common cause of difficulty with regular expressions nonetheless. When using backreferences, always double check that you are really capturing what you want.
When editing text, doubled words such as "the the" easily creep in. Using the regex \b ( \w + ) \s + \1 \b in your text editor , you can easily find them. To delete the second word, simply type in \1 as the replacement text and click the Replace button.
Parentheses cannot be used inside character classes , at least not as metacharacters. When you put a parenthesis in a character class, it is treated as a literal character. So the regex [ (a)b ] matches a , b , ( , and ) .
Backreferences, too, cannot be used inside a character class. The \1 in a regex like ( a ) [ \1 b ] is either an error or a needlessly escaped literal 1. In JavaScript it's an octal escape .
The previous topic on backreferences applies to all regex flavors, except those few that don't support backreferences at all. Flavors behave differently when you start doing things that don't fit the "match the text matched by a previous capturing group" job description.
There is a difference between a backreference to a capturing group that matched nothing, and one to a capturing group that did not participate in the match at all. The regex ( q ? ) b \1 matches b . q ? is optional and matches nothing, causing ( q ? ) to successfully match and capture nothing. b matches b and \1 successfully matches the nothing captured by the group.
In most flavors, the regex ( q ) ? b \1 fails to match b . ( q ) fails to match at all, so the group never gets to capture anything at all. Because the whole group is optional, the engine does proceed to match b . The engine now arrives at \1 which references a group that did not participate in the match attempt at all. This causes the backreference to fail to match at all, mimicking the result of the group. Since there's no ? making \1 optional, the overall match attempt fails.
One of the few exceptions is JavaScript . According to the official ECMA standard, a backreference to a non-participating capturing group must successfully match nothing just like a backreference to a participating group that captured nothing does. In other words, in JavaScript, ( q ? ) b \1 and ( q ) ? b \1 both match b . XPath also works this way.
Dinkumware's implementation of std::regex handles backreferences like JavaScript for all its grammars that support backreferences. Boost did so too until version 1.46. As of version 1.47, Boost fails backreferences to non-participating groups when using the ECMAScript grammar, but still lets them successfully match nothing when using the basic and grep grammars.
Backreferences to groups that do not exist, such as ( one ) \7 , are an error in most regex flavors. There are exceptions though. JavaScript treats \1 through \7 as octal escapes when there are fewer capturing groups in the regex than the digit after the backslash. \8 and \9 are an error because 8 and 9 are not valid octal digits.
Java treats backreferences to groups that don't exist as backreferences to groups that exist but never participate in the match. They are not an error, but simply never match anything.
.NET is a little more complicated. .NET supports single-digit and double-digit backreferences as well as double-digit octal escapes without a leading zero. Backreferences trump octal escapes. So \12 is a line feed (octal 12 = decimal 10) in a regex with fewer than 12 capturing groups. It would be a backreference to the 12th group in a regex with 12 or more capturing groups. .NET does not support single-digit octal escapes. So \7 is an error in a regex with fewer than 7 capturing groups.
Many modern regex flavors, including JGsoft , .NET , Java , Perl , PCRE , PHP , Delphi , and Ruby allow forward references. They allow you to use a backreference to a group that appears later in the regex. Forward references are obviously only useful if they're inside a repeated group. Then there can be situations in which the regex engine evaluates the backreference after the group has already matched. Before the group is attempted, the backreference fails like a backreference to a failed group does.
If forward references are supported, the regex ( \2 two | ( one ) ) + matches oneonetwo . At the start of the string, \2 fails. Trying the other alternative , one is matched by the second capturing group, and subsequently by the first group. The first group is then repeated. This time, \2 matches one as captured by the second group. two then matches two . With two repetitions of the first group, the regex has matched the whole subject string.
JavaScript does not support forward references, but does not treat them as an error. In JavaScript, forward references always find a zero-length match, just as backreferences to non-participating groups do in JavaScript. Because this is not particularly useful, XRegExp makes them an error. In std::regex , Boost , Python , Tcl , and VBScript forward references are an error.
A nested reference is a backreference inside the capturing group that it references. Like forward references, nested references are only useful if they're inside a repeated group, as in ( \1 two | ( one ) ) + . When nested references are supported, this regex also matches oneonetwo . At the start of the string, \1 fails. Trying the other alternative , one is matched by the second capturing group, and subsequently by the first group. The first group is then repeated. This time, \1 matches one as captured by the last iteration of the first group. It doesn't matter that the regex engine has re-entered the first group. The text matched by the group was stored into the backreference when the group was previously exited. two then matches two . With two repetitions of the first group, the regex has matched the whole subject string. If you retrieve the text from the capturing groups after the match, the first group stores onetwo while the second group captured the first occurrence of one in the string.
The JGsoft , .NET , Java , Perl , and VBScript flavors all support nested references. PCRE does too, but had bugs with backtracking into capturing groups with nested backreferences. Instead of fixing the bugs, PCRE 8.01 worked around them by forcing capturing groups with nested references to be atomic . So in PCRE, ( \1 two | ( one ) ) + is the same as (?> ( \1 two | ( one ) ) ) + . This affects languages with regex engines based on PCRE, such as PHP , Delphi , and R .
JavaScript and Ruby do not support nested references, but treat them as backreferences to non-participating groups instead of as errors. In JavaScript that means they always match a zero-length string, while in Ruby they always fail to match. In std::regex , Boost , Python , and Tcl , nested references are an error.
Nearly all modern regular expression engines support numbered capturing groups and numbered backreferences . Long regular expressions with lots of groups and backreferences may be hard to read. They can be particularly difficult to maintain as adding or removing a capturing group in the middle of the regex upsets the numbers of all the groups that follow the added or removed group.
Python's re module was the first to offer a solution: named capturing groups and named backreferences. (?P<name> group ) captures the match of group into the backreference "name". name must be an alphanumeric sequence starting with a letter. group can be any regular expression. You can reference the contents of the group with the named backreference (?P=name) . The question mark, P, angle brackets, and equals signs are all part of the syntax. Though the syntax for the named backreference uses parentheses, it's just a backreference that doesn't do any capturing or grouping. The HTML tags example can be written as < (?P<tag> [ A - Z ] [ A - Z 0 - 9 ] * ) \b [ ^ > ] * > . * ? </ (?P=tag) > .
The .NET framework also supports named capture. Microsoft's developers invented their own syntax, rather than follow the one pioneered by Python and copied by PCRE (the only two regex engines that supported named capture at that time). (?<name> group ) or (?'name' group ) captures the match of group into the backreference "name". The named backreference is \k<name> or \k'name' . Compared with Python, there is no P in the syntax for named groups. The syntax for named backreferences is more similar to that of numbered backreferences than to what Python uses. You can use single quotes or angle brackets around the name. This makes absolutely no difference in the regex. You can use both styles interchangeably. The syntax using angle brackets is preferable in programming languages that use single quotes to delimit strings, while the syntax using single quotes is preferable when adding your regex to an XML file, as this minimizes the amount of escaping you have to do to format your regex as a literal string or as XML content.
Because Python and .NET introduced their own syntax, we refer to these two variants as the "Python syntax" and the ".NET syntax" for named capture and named backreferences. Today, many other regex flavors have copied this syntax.
Perl 5.10 added support for both the Python and .NET syntax for named capture and backreferences. It also adds two more syntactic variants for named backreferences: \k{one} and \g{two} . There's no difference between the five syntaxes for named backreferences in Perl. All can be used interchangeably. In the replacement text, you can interpolate the variable $+{name} to insert the text matched by a named capturing group.
PCRE 7.2 and later support all the syntax for named capture and backreferences that Perl 5.10 supports. Old versions of PCRE supported the Python syntax, even though that was not "Perl-compatible" at the time. Languages like PHP , Delphi , and R that implement their regex support using PCRE also support all this syntax. Unfortunately, neither PHP or R support named references in the replacement text. You'll have to use numbered references to the named groups. PCRE does not support search-and-replace at all.
Java 7 and XRegExp copied the .NET syntax, but only the variant with angle brackets. Ruby 1.9 and supports both variants of the .NET syntax. The JGsoft flavor supports the Python syntax and both variants of the .NET syntax.
Boost 1.42 and later support named capturing groups using the .NET syntax with angle brackets or quotes and named backreferences using the \g syntax with curly braces from Perl 5.10. Boost 1.47 additionally supports backreferences using the \k syntax with angle brackets and quotes from .NET. Boost 1.47 allowed these variants to multiply. Boost 1.47 allows named and numbered backreferences to be specified with \g or \k and with curly braces, angle brackets, or quotes. So Boost 1.47 and later have six variations of the backreference syntax on top of the basic \1 syntax. This puts Boost in conflict with Ruby, PCRE, PHP, R, and JGsoft which treat \g with angle brackets or quotes as a subroutine call .
Mixing named and numbered capturing groups is not recommended because flavors are inconsistent in how the groups are numbered. If a group doesn't need to have a name, make it non-capturing using the (?: group ) syntax. In .NET you can make all unnamed groups non-capturing by setting RegexOptions.ExplicitCapture . In Delphi , set roExplicitCapture . With XRegExp , use the /n flag. Perl supports /n starting with Perl 5.22. With PCRE , set PCRE_NO_AUTO_CAPTURE . The JGsoft flavor and .NET support the mode modifier . If you make all unnamed groups non-capturing, you can skip this section and save yourself a headache.
Most flavors number both named and unnamed capturing groups by counting their opening parentheses from left to right. Adding a named capturing group to an existing regex still upsets the numbers of the unnamed groups. In .NET, however, unnamed capturing groups are assigned numbers first, counting their opening parentheses from left to right, skipping all named groups. After that, named groups are assigned the numbers that follow by counting the opening parentheses of the named groups from left to right.
The JGsoft regex engine copied the Python and the .NET syntax at a time when only Python and PCRE used the Python syntax, and only .NET used the .NET syntax. Therefore it also copied the numbering behavior of both Python and .NET, so that regexes intended for Python and .NET would keep their behavior. It numbers Python-style named groups along unnamed ones, like Python does. It numbers .NET-style named groups afterward, like .NET does. These rules apply even when you mix both styles in the same regex.
As an example, the regex ( a ) (?P<x> b ) ( c ) (?P<y> d ) matches abcd as expected. If you do a search-and-replace with this regex and the replacement \1 \2 \3 \4 or $1 $2 $3 $4 (depending on the flavor), you will get abcd . All four groups were numbered from left to right, from one till four.
Things are a bit more complicated with the .NET framework. The regex ( a ) (?<x> b ) ( c ) (?<y> d ) again matches abcd . However, if you do a search-and-replace with $1$2$3$4 as the replacement, you will get acbd . First, the unnamed groups ( a ) and ( c ) got the numbers 1 and 2. Then the named groups "x" and "y" got the numbers 3 and 4.
In all other flavors that copied the .NET syntax the regex ( a ) (?<x> b ) ( c ) (?<y> d ) still matches abcd . But in all those flavors, except the JGsoft flavor, the replacement \1 \2 \3 \4 or $1 $2 $3 $4 (depending on the flavor) gets you abcd . All four groups were numbered from left to right.
In PowerGREP , which uses the JGsoft flavor, named capturing groups play a special role. Groups with the same name are shared between all regular expressions and replacement texts in the same PowerGREP action. This allows captured by a named capturing group in one part of the action to be referenced in a later part of the action. Because of this, PowerGREP does not allow numbered references to named capturing groups at all. When mixing named and numbered groups in a regex, the numbered groups are still numbered following the Python and .NET rules, like the JGsoft flavor always does.
The .NET framework and the JGsoft flavor allow multiple groups in the regular expression to have the same name. All groups with the same name share the same storage for the text they match. Thus, a backreference to that name matches the text that was matched by the group with that name that most recently captured something. A reference to the name in the replacement text inserts the text matched by the group with that name that was the last one to capture something.
Perl and Ruby also allow groups with the same name. But these flavors only use smoke and mirrors to make it look like the all the groups with the same name act as one. In reality, the groups are separate. In Perl, a backreference matches the text captured by the leftmost group in the regex with that name that matched something. In Ruby, a backreference matches the text captured by any of the groups with that name. Backtracking makes Ruby try all the groups.
So in Perl and Ruby, you can only meaningfully use groups with the same name if they are in separate alternatives in the regex, so that only one of the groups with that name could ever capture any text. Then backreferences to that group sensibly match the text captured by the group.
For example, if you want to match "a" followed by a digit 0..5, or "b" followed by a digit 4..7, and you only care about the digit, you could use the regex a (?<digit> [ 0 - 5 ] ) | b (?<digit> [ 4 - 7 ] ) . In these four flavors, the group named "digit" will then give you the digit 0..7 that was matched, regardless of the letter. If you want this match to be followed by c and the exact same digit, you could use (?: a (?<digit> [ 0 - 5 ] ) | b (?<digit> [ 4 - 7 ] ) ) c \k<digit>
PCRE does not allow duplicate named groups by default. PCRE 6.7 and later allow them if you turn on that option or use the mode modifier . But prior to PCRE 8.36 that wasn't very useful as backreferences always pointed to the first capturing group with that name in the regex regardless of whether it participated in the match. Starting with PCRE 8.36 (and thus PHP 5.6.9 and R 3.1.3) and also in PCRE2, backreferences point to the first group with that name that actually participated in the match. Though PCRE and Perl handle duplicate groups in opposite directions the end result is the same if you follow the advice to only use groups with the same name in separate alternatives.
Boost allows duplicate named groups. Prior to Boost 1.47 that wasn't useful as backreferences always pointed to the last group with that name that appears before the backreference in the regex. In Boost 1.47 and later backreferences point to the first group with that name that actually participated in the match just like in PCRE 8.36 and later.
Python, Java, and XRegExp 3 do not allow multiple groups to use the same name. Doing so will give a regex compilation error. XRegExp 2 allowed them, but did not handle them correctly.
In Perl 5.10, PCRE 8.00, PHP 5.2.14, and Boost 1.42 (or later versions of these) it is best to use a branch reset group when you want groups in different alternatives to have the same name, as in (?| a (?<digit> [ 0 - 5 ] ) | b (?<digit> [ 4 - 7 ] ) ) c \k<digit> . With this special syntax—group opened with (?| instead of (?: —the two groups named "digit" really are one and the same group. Then backreferences to that group are always handled correctly and consistently between these flavors. (Older versions of PCRE and PHP may support branch reset groups, but don't correctly handle duplicate names in branch reset groups.)
Some applications support relative backreferences. These use a negative number to reference a group preceding the backreference. To find the group that the relative backreference refers to, take the absolute number of the backreference and count that many opening parentheses of (named or unnamed) capturing groups starting at the backreference and going from right to left through the regex. So ( a ) ( b ) ( c ) \k<-1> matches abcc and ( a ) ( b ) ( c ) \k<-3> matches abca . If the backreference is inside a capturing group, then you also need to count that capturing group's opening parenthesis. So ( a ) ( b ) ( c \k<-2> ) matches abcb . ( a ) ( b ) ( c \k<-1> ) either fails to match or is an error depending on whether your application allows nested backreferences .
The syntax for nested backreferences varies widely. It is generally an extension of the syntax for named backreferences . JGsoft V2 and Ruby 1.9 and later support \k<-1> and \k'-1' . Though this looks like the .NET syntax for named capture, .NET itself does not support relative backreferences.
Perl 5.10, PCRE 7.0, PHP 5.2.2, and R support \g{-1} and \g-1 .
Boost supports the Perl syntax starting with Boost 1.42. Boost adds the Ruby syntax starting with Boost 1.47. To complicate matters, Boost 1.47 allowed these variants to multiply. Boost 1.47 and later allow relative backreferences to be specified with \g or \k and with curly braces, angle brackets, or quotes. That makes six variations plus \g-1 for a total of seven variations. This puts Boost in conflict with Ruby, PCRE, PHP, R, and JGsoft which treat \g with angle brackets or quotes and a negative number as a relative subroutine call .
Perl 5.10 introduced a new regular expression feature called a branch reset group. JGsoft V2 and PCRE 7.2 and later also support this, as do languages like PHP , Delphi , and R that have regex functions based on PCRE. Boost added them to its ECMAScript grammar in version 1.42.
Alternatives inside a branch reset group share the same capturing groups. The syntax is (?| regex ) where (?| opens the group and regex is any regular expression. If you don't use any alternation or capturing groups inside the branch reset group, then its special function doesn't come into play. It then acts as a non-capturing group .
The regex (?| ( a ) | ( b ) | ( c ) ) consists of a single branch reset group with three alternatives. This regex matches either a , b , or c . The regex has only a single capturing group with number 1 that is shared by all three alternatives. After the match, $1 holds a , b , or c .
Compare this with the regex ( a ) | ( b ) | ( c ) that lacks the branch reset group. This regex also matches a , b , or c . But it has three capturing groups. After the match, $1 holds a or nothing at all, $2 holds b or nothing at all, while $3 holds c or nothing at all.
Backreferences to capturing groups inside branch reset groups work like you'd expect. (?| ( a ) | ( b ) | ( c ) ) \1 matches aa , bb , or cc . Since only one of the alternatives inside the branch reset group can match, the alternative that participates in the match determines the text stored by the capturing group and thus the text matched by the backreference.
The alternatives in the branch reset group don't need to have the same number of capturing groups. (?| abc | ( d ) ( e ) ( f ) | g ( h ) i ) has three capturing groups. When this regex matches abc , all three groups are empty. When def is matched, $1 holds d , $2 holds e and $3 holds f . When ghi is matched, $1 holds h while the other two are empty.
You can have capturing groups before and after the branch reset group. Groups before the branch reset group are numbered as usual. Groups in the branch reset group are numbered continued from the groups before the branch reset group, which each alternative resetting the number. Groups after the branch reset group are numbered continued from the alternative with the most groups, even if that is not the last alternative. So ( x ) (?| abc | ( d ) ( e ) ( f ) | g ( h ) i ) ( y ) defines five capturing groups. ( x ) is group 1, ( d ) and ( h ) are group 2, ( e ) is group 3, ( f ) is group 4, and ( y ) is group 5.
You can use named capturing groups inside branch reset groups. If you do, you should use the same names for the groups that will get the same numbers. Otherwise you'll get undesirable behavior in Perl or Boost. PowerGREP treats mismatched group names as an error. PCRE only reliably supports named groups inside branch reset groups starting with version 8.00. This means Delphi only does so starting with XE7 and PHP starting with version 5.2.14.
(?'before' x ) (?| abc | (?'left' d ) (?'middle' e ) (?'right' f ) | g (?'left' h ) i ) (?'after' y ) is the same as the previous regex. It names the five groups "before", "left", "middle", "right", and "after". Notice that because the 3rd alternative has only one capturing group, that must be the name of the first group in the other alternatives.
If you omit the names in some alternatives, the groups will still share the names with the other alternatives. In the regex (?'before' x ) (?| abc | (?'left' d ) (?'middle' e ) (?'right' f ) | g ( h ) i ) (?'after' y ) the group ( h ) is still named "left" because the branch reset group makes it share the name and number of (?'left' d ) .
In Perl, PCRE, and Boost, it is best to use a branch reset group when you want groups in different alternatives to have the same name . That's the only way in Perl, PCRE, and Boost to make sure that groups with the same name really are one and the same group.
In PowerGREP, groups with the same name are always treated as one and the same group. So you don't really need to use a branch reset group in PowerGREP when using named capturing groups.
It's time for a more practical example. These two regular expressions match a date in m/d or mm/dd format. They exclude invalid dates such as 2/31.
^
(?:
(
0
?
[
13578
]
|
1
[
02
]
)
/
(
[
012
]
?
[
0
-
9
]
|
3
[
01
]
)
# 31 days
|
(
0
?
[
469
]
|
11
)
/
(
[
012
]
?
[
0
-
9
]
|
30
)
# 30 days
|
(
0
?
2
)
/
(
[
012
]
?
[
0
-
9
]
)
# 29 days
)
$
The first version uses a non-capturing group (?:…) to group the alternatives. It has six separate capturing groups. $1 and $2 would hold the month and the day for months with 31 days, $3 and $4 for months with 30 days, and $5 and $6 would only be used for February.
^
(?|
(
0
?
[
13578
]
|
1
[
02
]
)
/
(
[
012
]
?
[
0
-
9
]
|
3
[
01
]
)
# 31 days
|
(
0
?
[
469
]
|
11
)
/
(
[
012
]
?
[
0
-
9
]
|
30
)
# 30 days
|
(
0
?
2
)
/
(
[
012
]
?
[
0
-
9
]
)
# 29 days
)
$
The second version uses a branch reset group (?|…) to group the alternatives and merge their capturing groups. Now there are only two capturing groups that are shared between the tree alternatives. When a match is found, $1 always holds the month, and 2 always holds the day, regardless of the number of days in the month.
Most modern regex flavors support a variant of the regular expression syntax called free-spacing mode. This mode allows for regular expressions that are much easier for people to read. Of the flavors discussed in this tutorial, only XML Schema and the POSIX and GNU flavors don't support it. Plain JavaScript doesn't either, but XRegExp does. The mode is usually enabled by setting an option or flag outside the regex. With flavors that support mode modifiers , you can put the very start of the regex to make the remainder of the regex free-spacing.
In free-spacing mode, whitespace between regular expression tokens is ignored. Whitespace includes spaces, tabs, and line breaks. Note that only whitespace between tokens is ignored. a b c is the same as abc in free-spacing mode. But \ d and \d are not the same. The former matches d , while the latter matches a digit. \d is a single regex token composed of a backslash and a "d". Breaking up the token with a space gives you an escaped space (which matches a space), and a literal "d".
Likewise, grouping modifiers cannot be broken up. (?> atomic ) is the same as (?> ato mic ) and as ( ?> ato mic ) . They all match the same atomic group . They're not the same as (? >atomic ) . The latter is a syntax error. The ?> grouping modifier is a single element in the regex syntax, and must stay together. This is true for all such constructs, including lookaround , named groups , etc.
Exactly which spaces and line breaks are ignored depends on the regex flavor. All flavors discussed in this tutorial ignore the ASCII space, tab, line feed, carriage return, and form feed characters. JGsoft V2 and Boost are the only flavors that ignore all Unicode spaces and line breaks. JGsoft V1 almost does but misses the next line control character (U+0085). Perl always treats non-ASCII spaces as literals. Perl 5.22 and later ignore non-ASCII line breaks. Perl 5.16 and prior treat them as literals. Perl 5.18 and 5.20 treated unescaped non-ASCII line breaks as errors in free-spacing mode to give developers a transition period.
A character class is also treated as a single token. [ abc ] is not the same as [ a b c ] . The former matches one of three letters, while the latter matches those three letters or a space. In other words: free-spacing mode has no effect inside character classes. Spaces and line breaks inside character classes will be included in the character class. This means that in free-spacing mode, you can use \ or [ ] to match a single space. Use whichever you find more readable. The hexadecimal escape \x20 also works, of course.
Java , however, does not treat a character class as a single token in free-spacing mode. Java does ignore spaces, line breaks, and comments inside character classes. So in Java's free-spacing mode, [ abc ] is identical to [ a b c ] . To add a space to a character class, you'll have to escape it with a backslash. But even in free-spacing mode, the negating caret must appear immediately after the opening bracket. [ ^ a b c ] matches any of the four characters ^ , a , b or c just like [ abc^ ] would. With the negating caret in the proper place, [ ^ a b c ] matches any character that is not a , b or c .
Perl 5.26 offers limited free-spacing within character classes as an option. The /x flag enables free-spacing outside character classes only, as in previous versions of Perl. The double /xx flag additionally makes Perl 5.26 treat unescaped spaces and tabs inside character classes as free whitespace. Line breaks are still literals inside character classes.
Java treats the ^ in [ ^ a ] as a literal. Even when spaces are ignored they still break the special meaning of the caret in Java. Perl 5.26 treats ^ in [ ^ a ] as a negation caret in /xx mode. Perl 5.26 totally ignores free whitespace. It still considers the caret to be at the start of the character class.
Another feature of free-spacing mode is that the # character starts a comment. The comment runs until the end of the line. Everything from the # until the next newline character is ignored. Most flavors do not recognize any other line break characters as the end of a comment, even if they recognize other line breaks as free whitespace or allow anchors to match at other line breaks . JGsoft V2 is the only flavor that recognizes all Unicode line breaks. Boost misses the vertical tab.
XPath and Oracle do not support comments within the regular expression, even though they have a free-spacing mode. They always treat # as a literal character.
Java is the only flavor that treats # as the start of a comment inside character classes in free-spacing mode. The comment runs until the end of the line, so you can use a ] to close a comment. All other flavors treat # as a literal inside character classes. That includes Perl 5.26 in /xx mode.
Putting it all together, the regex to match a valid date can be clarified by writing it across multiple lines:
# Match a 20th or 21st century date in yyyy-mm-dd format
(
19
|
20
)
\d
\d
# year (group 1)
[
- /.
]
# separator
(
0
[
1
-
9
]
|
1
[
012
]
)
# month (group 2)
[
- /.
]
# separator
(
0
[
1
-
9
]
|
[
12
]
[
0
-
9
]
|
3
[
01
]
)
# day (group 3)
Many flavors also allow you to add comments to your regex without using free-spacing mode. The syntax is (?#comment) where "comment" can be whatever you want, as long as it does not contain a closing parenthesis. The regex engine ignores everything after the (?# until the first closing parenthesis.
Of the flavors discussed in this tutorial, all flavors that support comment in free-spacing mode, except Java and Tcl , also support (?#comment) . The flavors that don't support comments in free-spacing mode or don't support free-spacing mode at all don't support (?#comment) either.
Unicode is a character set that aims to define all characters and glyphs from all human languages, living and dead. With more and more software being required to support multiple languages, or even just any language, Unicode has been strongly gaining popularity in recent years. Using different character sets for different languages is simply too cumbersome for programmers and users.
Unfortunately, Unicode brings its own requirements and pitfalls when it comes to regular expressions. Of the regex flavors discussed in this tutorial, Java , XML and the .NET framework use Unicode-based regex engines. Perl supports Unicode starting with version 5.6. PCRE can optionally be compiled with Unicode support . Note that PCRE is far less flexible in what it allows for the \p tokens, despite its name "Perl-compatible". The PHP preg functions , which are based on PCRE, support Unicode when the /u option is appended to the regular expression. Ruby supports Unicode escapes and properties in regular expressions starting with version 1.9. XRegExp brings support for Unicode properties to JavaScript.
RegexBuddy's regex engine is fully Unicode-based starting with version 2.0.0. RegexBuddy 1.x.x did not support Unicode at all. PowerGREP uses the same Unicode regex engine starting with version 3.0.0. Earlier versions would convert Unicode files to ANSI prior to grepping with an 8-bit (i.e. non-Unicode) regex engine. EditPad Pro supports Unicode starting with version 6.0.0.
Most people would consider à a single character. Unfortunately, it need not be depending on the meaning of the word "character".
All Unicode regex engines discussed in this tutorial treat any single Unicode code point as a single character. When this tutorial tells you that the dot matches any single character , this translates into Unicode parlance as "the dot matches any single Unicode code point". In Unicode, à can be encoded as two code points: U+0061 (a) followed by U+0300 (grave accent). In this situation, . applied to à will match a without the accent. ^ . $ will fail to match, since the string consists of two code points. ^ . . $ matches à .
The Unicode code point U+0300 (grave accent) is a combining mark . Any code point that is not a combining mark can be followed by any number of combining marks. This sequence, like U+0061 U+0300 above, is displayed as a single grapheme on the screen.
Unfortunately, à can also be encoded with the single Unicode code point U+00E0 (a with grave accent). The reason for this duality is that many historical character sets encode "a with grave accent" as a single character. Unicode's designers thought it would be useful to have a one-on-one mapping with popular legacy character sets, in addition to the Unicode way of separating marks and base letters (which makes arbitrary combinations not supported by legacy character sets possible).
Matching a single grapheme, whether it's encoded as a single code point, or as multiple code points using combining marks, is easy in Perl, PCRE, PHP, Boost, Ruby 2.0, and the Just Great Software applications: simply use \X . You can consider \X the Unicode version of the dot . There is one difference, though: \X always matches line break characters, whereas the dot does not match line break characters unless you enable the dot matches newline matching mode .
In Java, .NET, and Ruby 1.9 you can use \P{M} \p{M} * + or (?> \P{M} \p{M} * ) as a reasonably close substitute. To match any number of graphemes, use (?> \P{M} \p{M} * ) + as a substitute for \X + .
To match a specific Unicode code point, use \uFFFF where FFFF is the hexadecimal number of the code point you want to match. You must always specify 4 hexadecimal digits E.g. \u00E0 matches à , but only when encoded as a single code point U+00E0.
Perl , PCRE , Boost , and std::regex do not support the \uFFFF syntax. They use \x{FFFF} instead. You can omit leading zeros in the hexadecimal number between the curly braces. Since \x by itself is not a valid regex token, \x{1234} can never be confused to match \x 1234 times. It always matches the Unicode code point U+1234. \x{1234} {5678} will try to match code point U+1234 exactly 5678 times.
In Java, the regex token \uFFFF only matches the specified code point, even when you turned on canonical equivalence. However, the same syntax \uFFFF is also used to insert Unicode characters into literal strings in the Java source code. Pattern.compile("\u00E0") will match both the single-code-point and double-code-point encodings of à , while Pattern.compile("\\u00E0") matches only the single-code-point version. Remember that when writing a regex as a Java string literal, backslashes must be escaped. The former Java code compiles the regex à , while the latter compiles \u00E0 . Depending on what you're doing, the difference may be significant.
JavaScript , which does not offer any Unicode support through its RegExp class, does support \uFFFF for matching a single Unicode code point as part of its string syntax.
XML Schema and XPath do not have a regex token for matching Unicode code points. However, you can easily use XML entities like  to insert literal code points into your regular expression.
In addition to complications, Unicode also brings new possibilities. One is that each Unicode character belongs to a certain category. You can match a single character belonging to the "letter" category with \p{L} . You can match a single character not belonging to that category with \P{L} .
Again, "character" really means "Unicode code point". \p{L} matches a single code point in the category "letter". If your input string is à encoded as U+0061 U+0300, it matches a without the accent. If the input is à encoded as U+00E0, it matches à with the accent. The reason is that both the code points U+0061 (a) and U+00E0 (à) are in the category "letter", while U+0300 is in the category "mark".
You should now understand why \P{M} \p{M} * + is the equivalent of \X . \P{M} matches a code point that is not a combining mark, while \p{M} * + matches zero or more code points that are combining marks. To match a letter including any diacritics, use \p{L} \p{M} * + . This last regex will always match à , regardless of how it is encoded. The possessive quantifier makes sure that backtracking doesn't cause \P{M} \p{M} * + to match a non-mark without the combining marks that follow it, which \X would never do.
PCRE, PHP, and .NET are case sensitive when it checks the part between curly braces of a \p token. \p{Zs} will match any kind of space character, while \p{zs} will throw an error. All other regex engines described in this tutorial will match the space in both cases, ignoring the case of the category between the curly braces. Still, I recommend you make a habit of using the same uppercase and lowercase combination as I did in the list of properties below. This will make your regular expressions work with all Unicode regex engines.
In addition to the standard notation, \p{L} , Java, Perl, PCRE, the JGsoft engine , and XRegExp 3 allow you to use the shorthand \pL . The shorthand only works with single-letter Unicode properties. \pL l is not the equivalent of \p{Ll} . It is the equivalent of \p{L} l which matches Al or àl or any Unicode letter followed by a literal l .
Perl, XRegExp, and the JGsoft engine also support the longhand \p{Letter} . You can find a complete list of all Unicode properties below. You may omit the underscores or use hyphens or spaces instead.
The Unicode standard places each assigned code point (character) into one script. A script is a group of code points used by a particular human writing system. Some scripts like Thai correspond with a single human language. Other scripts like Latin span multiple languages.
Some languages are composed of multiple scripts. There is no Japanese Unicode script. Instead, Unicode offers the Hiragana , Katakana , Han , and Latin scripts that Japanese documents are usually composed of.
A special script is the Common script. This script contains all sorts of characters that are common to a wide range of scripts. It includes all sorts of punctuation, whitespace and miscellaneous symbols.
All assigned Unicode code points (those matched by \P{Cn} ) are part of exactly one Unicode script. All unassigned Unicode code points (those matched by \p{Cn} ) are not part of any Unicode script at all.
The JGsoft engine , Perl , PCRE , PHP , Ruby 1.9 , Delphi , and XRegExp can match Unicode scripts. Here's a list:
Perl and the JGsoft flavor allow you to use \p{IsLatin} instead of \p{Latin} . The "Is" syntax is useful for distinguishing between scripts and blocks, as explained in the next section. PCRE, PHP, and XRegExp do not support the "Is" prefix.
Java 7 adds support for Unicode scripts. Unlike the other flavors, Java 7 requires the "Is" prefix.
The Unicode standard divides the Unicode character map into different blocks or ranges of code points. Each block is used to define characters of a particular script like "Tibetan" or belonging to a particular group like "Braille Patterns". Most blocks include unassigned code points, reserved for future expansion of the Unicode standard.
Note that Unicode blocks do not correspond 100% with scripts. An essential difference between blocks and scripts is that a block is a single contiguous range of code points, as listed below. Scripts consist of characters taken from all over the Unicode character map. Blocks may include unassigned code points (i.e. code points matched by \p{Cn} ). Scripts never include unassigned code points. Generally, if you're not sure whether to use a Unicode script or Unicode block, use the script.
For example, the Currency block does not include the dollar and yen symbols. Those are found in the Basic_Latin and Latin-1_Supplement blocks instead, even though both are currency symbols, and the yen symbol is not a Latin character. This is for historical reasons, because the ASCII standard includes the dollar sign, and the ISO-8859 standard includes the yen sign. You should not blindly use any of the blocks listed below based on their names. Instead, look at the ranges of characters they actually match. A tool like RegexBuddy can be very helpful with this. The Unicode property \p{Sc} or \p{Currency_Symbol} would be a better choice than the Unicode block \p{InCurrency_Symbols} when trying to find all currency symbols.
Not all Unicode regex engines use the same syntax to match Unicode blocks. Java , Ruby 2.0 , and XRegExp use the \p{InBlock} syntax as listed above. .NET and XML use \p{IsBlock} instead. Perl and the JGsoft flavor support both notations. I recommend you use the "In" notation if your regex engine supports it. "In" can only be used for Unicode blocks, while "Is" can also be used for Unicode properties and scripts, depending on the regular expression flavor you're using. By using "In", it's obvious you're matching a block and not a similarly named property or script.
In .NET and XML, you must omit the underscores but keep the hyphens in the block names. E.g. Use \p{IsLatinExtended-A} instead of \p{InLatin_Extended-A} . In Java, you must omit the hyphens. .NET and XML also compare the names case sensitively, while Perl, Ruby, and the JGsoft flavor compare them case insensitively. Java 4 is case sensitive. Java 5 and later are case sensitive for the "Is" prefix but not for the block names themselves.
The actual names of the blocks are the same in all regular expression engines. The block names are defined in the Unicode standard. PCRE and PHP do not support Unicode blocks, even though they support Unicode scripts.
While you should always keep in mind the pitfalls created by the different ways in which accented characters can be encoded, you don't always have to worry about them. If you know that your input string and your regex use the same style, then you don't have to worry about it at all. This process is called Unicode normalization . All programming languages with native Unicode support, such as Java, C# and VB.NET, have library routines for normalizing strings. If you normalize both the subject and regex before attempting the match, there won't be any inconsistencies.
If you are using Java, you can pass the CANON_EQ flag as the second parameter to Pattern.compile(). This tells the Java regex engine to consider canonically equivalent characters as identical. The regex à encoded as U+00E0 matches à encoded as U+0061 U+0300, and vice versa. None of the other regex engines currently support canonical equivalence while matching.
If you type the à key on the keyboard, all word processors that I know of will insert the code point U+00E0 into the file. So if you're working with text that you typed in yourself, any regex that you type in yourself will match in the same way.
Finally, if you're using PowerGREP to search through text files encoded using a traditional Windows (often called "ANSI") or ISO-8859 code page, PowerGREP always uses the one-on-one substitution. Since all the Windows or ISO-8859 code pages encode accented characters as a single code point, nearly all software uses a single Unicode code point for each character when converting the file to Unicode.
Normally, matching modes are specified outside the regular expression. In a programming language, you pass them as a flag to the regex constructor or append them to the regex literal. In an application, you'd toggle the appropriate buttons or checkboxes. You can find the specifics in the tools and languages section of this website.
Sometimes, the tool or language does not provide the ability to specify matching options. The handy String.matches() method in Java does not take a parameter for matching options like Pattern.compile() does. Or, the regex flavor may support matching modes that aren't exposed as external flags. The regex functions in R have ignore.case as their only option, even though the underlying PCRE library has more matching modes than any other discussed in this tutorial.
In those situation, you can add the following mode modifiers to the start of the regex. To specify multiple modes, simply put them together as in .
Modern regex flavors allow you to apply modifiers to only part of the regular expression. If you insert the modifier in the middle of the regex then the modifier only applies to the part of the regex to the right of the modifier. With these flavors, you can turn off modes by preceding them with a minus sign. All modes after the minus sign will be turned off. E.g. turns on case insensitivity, and turns off both single-line mode and multi-line mode.
Flavors that can't apply modifiers to only part of the regex treat a modifiers in the middle of the regex as an error. Python is an exception to this. In Python, putting a modifier in the middle of the regex affects the whole regex. So in Python, caseless and caseless are both case insensitive. In all other flavors, the trailing mode modifier either has no effect or is an error.
You can quickly test how the regex flavor you're using handles mode modifiers. The regex te st should match test and TEst , but not teST or TEST .
Instead of using two modifiers, one to turn an option on, and one to turn it off, you use a modifier span. caseless cased caseless is equivalent to caseless (? - i: cased ) caseless . This syntax resembles that of the non-capturing group (?: group ) . You could think of a non-capturing group as a modifier span that does not change any modifiers. But there are flavors, like JavaScript , Python , and Tcl that support non-capturing groups even though they do not support modifier spans. Like a non-capturing group, the modifier span does not create a backreference .
Modifier spans are supported by all regex flavors that allow you to use mode modifiers in the middle of the regular expression, and by those flavors only. These include the JGsoft engine , .NET , Java , Perl and PCRE , PHP , Delphi , and R .
An atomic group is a group that, when the regex engine exits from it, automatically throws away all backtracking positions remembered by any tokens inside the group. Atomic groups are non-capturing. The syntax is (?> group ) . Lookaround groups are also atomic. Atomic grouping is supported by most modern regular expression flavors, including the JGsoft flavor, Java , PCRE , .NET , Perl , Boost , and Ruby . Most of these also support possessive quantifiers , which are essentially a notational convenience for atomic grouping.
An example will make the behavior of atomic groups clear. The regular expression a ( bc | b ) c (capturing group) matches abcc and abc . The regex a (?> bc | b ) c (atomic group) matches abcc but not abc .
When applied to abc , both regexes will match a to a , bc to bc , and then c will fail to match at the end of the string. Here their paths diverge. The regex with the capturing group has remembered a backtracking position for the alternation. The group will give up its match, b then matches b and c matches c . Match found!
The regex with the atomic group, however, exited from an atomic group after bc was matched. At that point, all backtracking positions for tokens inside the group are discarded. In this example, the alternation's option to try b at the second position in the string is discarded. As a result, when c fails, the regex engine has no alternatives left to try.
Of course, the above example isn't very useful. But it does illustrate very clearly how atomic grouping eliminates certain matches. Or more importantly, it eliminates certain match attempts.
Consider the regex \b ( integer | insert | in ) \b and the subject integers . Obviously, because of the word boundaries , these don't match. What's not so obvious is that the regex engine will spend quite some effort figuring this out.
\b matches at the start of the string, and integer matches integer . The regex engine makes note that there are two more alternatives in the group, and continues with \b . This fails to match between the r and s . So the engine backtracks to try the second alternative inside the group. The second alternative matches in , but then fails to match s . So the engine backtracks once more to the third alternative. in matches in . \b fails between the n and t this time. The regex engine has no more remembered backtracking positions, so it declares failure.
This is quite a lot of work to figure out integers isn't in our list of words. We can optimize this by telling the regular expression engine that if it can't match \b after it matched integer , then it shouldn't bother trying any of the other words. The word we've encountered in the subject string is a longer word, and it isn't in our list.
We can do this by turning the capturing group into an atomic group: \b (?> integer | insert | in ) \b . Now, when integer matches, the engine exits from an atomic group, and throws away the backtracking positions it stored for the alternation. When \b fails, the engine gives up immediately. This savings can be significant when scanning a large file for a long list of keywords. This savings will be vital when your alternatives contain repeated tokens (not to mention repeated groups) that lead to catastrophic backtracking .
Don't be too quick to make all your groups atomic. As we saw in the first example above, atomic grouping can exclude valid matches too. Compare how \b (?> integer | insert | in ) \b and \b (?> in | integer | insert ) \b behave when applied to insert . The former regex matches, while the latter fails. If the groups weren't atomic, both regexes would match. Remember that alternation tries its alternatives from left to right. If the second regex matches in , it won't try the two other alternatives due to the atomic group.
The topic on repetition operators or quantifiers explains the difference between greedy and lazy repetition. Greediness and laziness determine the order in which the regex engine tries the possible permutations of the regex pattern. A greedy quantifier first tries to repeat the token as many times as possible, and gradually gives up matches as the engine backtracks to find an overall match. A lazy quantifier first repeats the token as few times as required, and gradually expands the match as the engine backtracks through the regex to find an overall match.
Because greediness and laziness change the order in which permutations are tried, they can change the overall regex match. However, they do not change the fact that the regex engine will backtrack to try all possible permutations of the regular expression in case no match can be found.
Possessive quantifiers are a way to prevent the regex engine from trying all permutations. This is primarily useful for performance reasons. You can also use possessive quantifiers to eliminate certain matches.
Of the regex flavors discussed in this tutorial, possessive quantifiers are supported by JGsoft , Java , and PCRE . That includes languages with regex support based on PCRE such as PHP , Delphi , and R . Ruby supports possessive quantifiers starting with Ruby 1.9, Perl supports them starting with Perl 5.10, and Boost starting with Boost 1.42.
Like a greedy quantifier, a possessive quantifier repeats the token as many times as possible. Unlike a greedy quantifier, it does not give up matches as the engine backtracks. With a possessive quantifier, the deal is all or nothing. You can make a quantifier possessive by placing an extra + after it. * is greedy, *? is lazy, and *+ is possessive. ++ , ?+ and {n,m}+ are all possessive as well.
Let's see what happens if we try to match " [ ^ " ] * + " against "abc" . The " matches the " . [ ^ " ] matches a , b and c as it is repeated by the star . The final " then matches the final " and we found an overall match. In this case, the end result is the same, whether we use a greedy or possessive quantifier. There is a slight performance increase though, because the possessive quantifier doesn't have to remember any backtracking positions.
The performance increase can be significant in situations where the regex fails. If the subject is "abc (no closing quote), the above matching process happens in the same way, except that the second " fails. When using a possessive quantifier, there are no steps to backtrack to. The regular expression does not have any alternation or non-possessive quantifiers that can give up part of their match to try a different permutation of the regular expression. So the match attempt fails immediately when the second " fails.
Had we used " [ ^ " ] * " with a greedy quantifier instead, the engine would have backtracked. After the " failed at the end of the string, the [ ^ " ] * would give up one match, leaving it with ab . The " would then fail to match c . [ ^ " ] * backtracks to just a , and " fails to match b . Finally, [ ^ " ] * backtracks to match zero characters, and " fails a . Only at this point have all backtracking positions been exhausted, and does the engine give up the match attempt. Essentially, this regex performs as many needless steps as there are characters following the unmatched opening quote.
The main practical benefit of possessive quantifiers is to speed up your regular expression. In particular, possessive quantifiers allow your regex to fail faster. In the above example, when the closing quote fails to match, we know the regular expression couldn't possibly have skipped over a quote. So there's no need to backtrack and check for the quote. We make the regex engine aware of this by making the quantifier possessive. In fact, some engines, including the JGsoft engine, detect that [ ^ " ] * and " are mutually exclusive when compiling your regular expression, and automatically make the star possessive.
Now, linear backtracking like a regex with a single quantifier does is pretty fast. It's unlikely you'll notice the speed difference. However, when you're nesting quantifiers, a possessive quantifier may save your day. Nesting quantifiers means that you have one or more repeated tokens inside a group, and the group is also repeated. That's when catastrophic backtracking often rears its ugly head. In such cases, you'll depend on possessive quantifiers and/or atomic grouping to save the day.
Using possessive quantifiers can change the result of a match attempt. Since no backtracking is done, and matches that would require a greedy quantifier to backtrack will not be found with a possessive quantifier. For example, " . * " matches "abc" in "abc"x , but " . * + " does not match this string at all.
In both regular expressions, the first " matches the first " in the string. The repeated dot then matches the remainder of the string abc"x . The second " then fails to match at the end of the string.
Now, the paths of the two regular expressions diverge. The possessive dot-star wants it all. No backtracking is done. Since the " failed, there are no permutations left to try, and the overall match attempt fails. The greedy dot-star, while initially grabbing everything, is willing to give back. It will backtrack one character at a time. Backtracking to abc" , " fails to match x . Backtracking to abc , " matches " . An overall match "abc" is found.
Essentially, the lesson here is that when using possessive quantifiers, you need to make sure that whatever you're applying the possessive quantifier to should not be able to match what should follow it. The problem in the above example is that the dot also matches the closing quote. This prevents us from using a possessive quantifier. The negated character class in the previous section cannot match the closing quote, so we can make it possessive.
Technically, possessive quantifiers are a notational convenience to place an atomic group around a single quantifier. All regex flavors that support possessive quantifiers also support atomic grouping. But not all regex flavors that support atomic grouping support possessive quantifiers. With those flavors, you can achieve the exact same results using an atomic group.
Basically, instead of X * + , write (?> X * ) . It is important to notice that both the quantified token X and the quantifier are inside the atomic group. Even if X is a group, you still need to put an extra atomic group around it to achieve the same effect. (?: a | b ) * + is equivalent to (?> (?: a | b ) * ) but not to (?> a | b ) * . The latter is a valid regular expression, but it won't have the same effect when used as part of a larger regular expression.
To illustrate, (?: a | b ) * + b and (?> (?: a | b ) * ) b both fail to match b . a | b matches the b . The star is satisfied, and the fact that it's possessive or the atomic group will cause the star to forget all its backtracking positions. The second b in the regex has nothing left to match, and the overall match attempt fails.
In the regex (?> a | b ) * b , the atomic group forces the alternation to give up its backtracking positions. This means that if an a is matched, it won't come back to try b if the rest of the regex fails. Since the star is outside of the group, it is a normal, greedy star. When the second b fails, the greedy star backtracks to zero iterations. Then, the second b matches the b in the subject string.
This distinction is particularly important when converting a regular expression written by somebody else using possessive quantifiers to a regex flavor that doesn't have possessive quantifiers. You could, of course, let a tool like RegexBuddy do the conversion for you.
Lookahead and lookbehind, collectively called "lookaround", are zero-length assertions just like the start and end of line , and start and end of word anchors explained earlier in this tutorial. The difference is that lookaround actually matches characters, but then gives up the match, returning only the result: match or no match. That is why they are called "assertions". They do not consume characters in the string, but only assert whether a match is possible or not. Lookaround allows you to create regular expressions that are impossible to create without them, or that would get very longwinded without them.
Negative lookahead is indispensable if you want to match something not followed by something else. When explaining character classes , this tutorial explained why you cannot use a negated character class to match a q not followed by a u . Negative lookahead provides the solution: q (?! u ) . The negative lookahead construct is the pair of parentheses, with the opening parenthesis followed by a question mark and an exclamation point. Inside the lookahead, we have the trivial regex u .
Positive lookahead works just the same. q (?= u ) matches a q that is followed by a u, without making the u part of the match. The positive lookahead construct is a pair of parentheses, with the opening parenthesis followed by a question mark and an equals sign.
You can use any regular expression inside the lookahead (but not lookbehind, as explained below). Any valid regular expression can be used inside the lookahead. If it contains capturing groups then those groups will capture as normal and backreferences to them will work normally, even outside the lookahead. (The only exception is Tcl , which treats all groups inside lookahead as non-capturing.) The lookahead itself is not a capturing group. It is not included in the count towards numbering the backreferences. If you want to store the match of the regex inside a lookahead, you have to put capturing parentheses around the regex inside the lookahead, like this: (?= ( regex ) ) . The other way around will not work, because the lookahead will already have discarded the regex match by the time the capturing group is to store its match.
First, let's see how the engine applies q (?! u ) to the string Iraq . The first token in the regex is the literal q . As we already know, this causes the engine to traverse the string until the q in the string is matched. The position in the string is now the void after the string. The next token is the lookahead. The engine takes note that it is inside a lookahead construct now, and begins matching the regex inside the lookahead. So the next token is u . This does not match the void after the string. The engine notes that the regex inside the lookahead failed. Because the lookahead is negative, this means that the lookahead has successfully matched at the current position. At this point, the entire regex has matched, and q is returned as the match.
Let's try applying the same regex to quit . q matches q . The next token is the u inside the lookahead. The next character is the u . These match. The engine advances to the next character: i . However, it is done with the regex inside the lookahead. The engine notes success, and discards the regex match. This causes the engine to step back in the string to u .
Because the lookahead is negative, the successful match inside it causes the lookahead to fail. Since there are no other permutations of this regex, the engine has to start again at the beginning. Since q cannot match anywhere else, the engine reports failure.
Let's take one more look inside, to make sure you understand the implications of the lookahead. Let's apply q (?= u ) i to quit . The lookahead is now positive and is followed by another token. Again, q matches q and u matches u . Again, the match from the lookahead must be discarded, so the engine steps back from i in the string to u . The lookahead was successful, so the engine continues with i . But i cannot match u . So this match attempt fails. All remaining attempts fail as well, because there are no more q's in the string.
Lookbehind has the same effect, but works backwards. It tells the regex engine to temporarily step backwards in the string, to check if the text inside the lookbehind can be matched there. (?<! a ) b matches a "b" that is not preceded by an "a", using negative lookbehind. It doesn't match cab , but matches the b (and only the b ) in bed or debt . (?<= a ) b (positive lookbehind) matches the b (and only the b ) in cab , but does not match bed or debt .
The construct for positive lookbehind is (?<= text ) : a pair of parentheses, with the opening parenthesis followed by a question mark, "less than" symbol, and an equals sign. Negative lookbehind is written as (?<! text ) , using an exclamation point instead of an equals sign.
Let's apply (?<= a ) b to thingamabob . The engine starts with the lookbehind and the first character in the string. In this case, the lookbehind tells the engine to step back one character, and see if a can be matched there. The engine cannot step back one character because there are no characters before the t . So the lookbehind fails, and the engine starts again at the next character, the h . (Note that a negative lookbehind would have succeeded here.) Again, the engine temporarily steps back one character to check if an "a" can be found there. It finds a t , so the positive lookbehind fails again.
The lookbehind continues to fail until the regex reaches the m in the string. The engine again steps back one character, and notices that the a can be matched there. The positive lookbehind matches. Because it is zero-length, the current position in the string remains at the m . The next token is b , which cannot match here. The next character is the second a in the string. The engine steps back, and finds out that the m does not match a .
The next character is the first b in the string. The engine steps back and finds out that a satisfies the lookbehind. b matches b , and the entire regex has been matched successfully. It matches one character: the first b in the string.
The good news is that you can use lookbehind anywhere in the regex, not only at the start. If you want to find a word not ending with an "s", you could use \b \w + (?<! s ) \b . This is definitely not the same as \b \w + [ ^ s ] \b . When applied to John's , the former matches John and the latter matches John' (including the apostrophe). I will leave it up to you to figure out why. (Hint: \b matches between the apostrophe and the s ). The latter also doesn't match single-letter words like "a" or "I". The correct regex without using lookbehind is \b \w * [ ^ s \W ] \b (star instead of plus, and \W in the character class). Personally, I find the lookbehind easier to understand. The last regex, which works correctly, has a double negation (the \W in the negated character class). Double negations tend to be confusing to humans. Not to regex engines, though. (Except perhaps for Tcl, which treats negated shorthands in negated character classes as an error.)
The bad news is that most regex flavors do not allow you to use just any regex inside a lookbehind, because they cannot apply a regular expression backwards. The regular expression engine needs to be able to figure out how many characters to step back before checking the lookbehind. When evaluating the lookbehind, the regex engine determines the length of the regex inside the lookbehind, steps back that many characters in the subject string, and then applies the regex inside the lookbehind from left to right just as it would with a normal regex.
Many regex flavors, including those used by Perl , Python , and Boost only allow fixed-length strings. You can use literal text , character escapes , Unicode escapes other than \X , and character classes . You cannot use quantifiers or backreferences . You can use alternation , but only if all alternatives have the same length. These flavors evaluate lookbehind by first stepping back through the subject string for as many characters as the lookbehind needs, and then attempting the regex inside the lookbehind from left to right.
PCRE is not fully Perl-compatible when it comes to lookbehind. While Perl requires alternatives inside lookbehind to have the same length, PCRE allows alternatives of variable length. PHP , Delphi , R , and Ruby also allow this. Each alternative still has to be fixed-length. Each alternative is treated as a separate fixed-length lookbehind.
Java takes things a step further by allowing finite repetition. You still cannot use the star or plus , but you can use the question mark and the curly braces with the max parameter specified. Java determines the minimum and maximum possible lengths of the lookbehind. The lookbehind in the regex (?<! a b {2,4} c {3,5} d ) test has 5 possible lengths. It can be from 7 through 11 characters long. When Java (version 6 or later) tries to match the lookbehind, it first steps back the minimum number of characters (7 in this example) in the string and then evaluates the regex inside the lookbehind as usual, from left to right. If it fails, Java steps back one more character and tries again. If the lookbehind continues to fail, Java continues to step back until the lookbehind either matches or it has stepped back the maximum number of characters (11 in this example). This repeated stepping back through the subject string kills performance when the number of possible lengths of the lookbehind grows. Keep this in mind. Don't choose an arbitrarily large maximum number of repetitions to work around the lack of infinite quantifiers inside lookbehind. Java 4 and 5 have bugs that cause lookbehind with alternation or variable quantifiers to fail when it should succeed in some situations. These bugs were fixed in Java 6.
The only regex engines that allow you to use a full regular expression inside lookbehind, including infinite repetition and backreferences, are the JGsoft engine and the .NET framework RegEx classes . These regex engines really apply the regex inside the lookbehind backwards, going through the regex inside the lookbehind and through the subject string from right to left. They only need to evaluate the lookbehind once, regardless of how many different possible lengths it has.
Finally, flavors like JavaScript , std::regex , and Tcl do not support lookbehind at all, even though they do support lookahead.
The fact that lookaround is zero-length automatically makes it atomic . As soon as the lookaround condition is satisfied, the regex engine forgets about everything inside the lookaround. It will not backtrack inside the lookaround to try different permutations.
The only situation in which this makes any difference is when you use capturing groups inside the lookaround. Since the regex engine does not backtrack into the lookaround, it will not try different permutations of the capturing groups.
For this reason, the regex (?= ( \d + ) ) \w + \1 never matches 123x12 . First the lookaround captures 123 into \1 . \w + then matches the whole string and backtracks until it matches only 1 . Finally, \w + fails since \1 cannot be matched at any position. Now, the regex engine has nothing to backtrack to, and the overall regex fails. The backtracking steps created by \d + have been discarded. It never gets to the point where the lookahead captures only 12 .
Obviously, the regex engine does try further positions in the string. If we change the subject string, the regex (?= ( \d + ) ) \w + \1 does match 56x56 in 456x56 .
If you don't use capturing groups inside lookaround, then all this doesn't matter. Either the lookaround condition can be satisfied or it cannot be. In how many ways it can be satisfied is irrelevant.
Lookaround , which was introduced in detail in the previous topic , is a very powerful concept. Unfortunately, it is often underused by people new to regular expressions, because lookaround is a bit confusing. The confusing part is that the lookaround is zero-length. So if you have a regex in which a lookahead is followed by another piece of regex, or a lookbehind is preceded by another piece of regex, then the regex traverses part of the string twice.
A more practical example makes this clear. Let's say we want to find a word that is six letters long and contains the three consecutive letters cat . Actually, we can match this without lookaround. We just specify all the options and lump them together using alternation : cat \w {3} | \w cat \w {2} | \w {2} cat \w | \w {3} cat . Easy enough. But this method gets unwieldy if you want to find any word between 6 and 12 letters long containing either "cat", "dog" or "mouse".
In this example, we basically have two requirements for a successful match. First, we want a word that is 6 letters long. Second, the word we found must contain the word "cat".
Matching a 6-letter word is easy with \b \w {6} \b . Matching a word containing "cat" is equally easy: \b \w * cat \w * \b .
Combining the two, we get: (?= \b \w {6} \b ) \b \w * cat \w * \b . Easy! Here's how this works. At each character position in the string where the regex is attempted, the engine first attempts the regex inside the positive lookahead. This sub-regex, and therefore the lookahead, matches only when the current character position in the string is at the start of a 6-letter word in the string. If not, the lookahead fails and the engine continues trying the regex from the start at the next character position in the string.
The lookahead is zero-length. So when the regex inside the lookahead has found the 6-letter word, the current position in the string is still at the beginning of the 6-letter word. The regex engine attempts the remainder of the regex at this position. Because we already know that a 6-letter word can be matched at the current position, we know that \b matches and that the first \w * matches 6 times. The engine then backtracks , reducing the number of characters matched by \w * , until cat can be matched. If cat cannot be matched, the engine has no other choice but to restart at the beginning of the regex, at the next character position in the string. This is at the second letter in the 6-letter word we just found, where the lookahead will fail, causing the engine to advance character by character until the next 6-letter word.
If cat can be successfully matched, the second \w * consumes the remaining letters, if any, in the 6-letter word. After that, the last \b in the regex is guaranteed to match where the second \b inside the lookahead matched. Our double-requirement-regex has matched successfully.
While the above regex works just fine, it is not the most optimal solution. This is not a problem if you are just doing a search in a text editor. But optimizing things is a good idea if this regex will be used repeatedly and/or on large chunks of data in an application you are developing.
You can discover these optimizations by yourself if you carefully examine the regex and follow how the regex engine applies it, as we did above. The third and last \b are guaranteed to match. Since word boundaries are zero-length, and therefore do not change the result returned by the regex engine, we can remove them, leaving: (?= \b \w {6} \b ) \w * cat \w * . Though the last \w * is also guaranteed to match, we cannot remove it because it adds characters to the regex match. Remember that the lookahead discards its match, so it does not contribute to the match returned by the regex engine. If we omitted the \w * , the resulting match would be the start of a 6-letter word containing "cat", up to and including "cat", instead of the entire word.
But we can optimize the first \w * . As it stands, it will match 6 letters and then backtrack. But we know that in a successful match, there can never be more than 3 letters before "cat". So we can optimize this to \w {0,3} . Note that making the asterisk lazy would not have optimized this sufficiently. The lazy asterisk would find a successful match sooner, but if a 6-letter word does not contain "cat", it would still cause the regex engine to try matching "cat" at the last two letters, at the last single letter, and even at one character beyond the 6-letter word.
So we have (?= \b \w {6} \b ) \w {0,3} cat \w * . One last, minor, optimization involves the first \b . Since it is zero-length itself, there's no need to put it inside the lookahead. So the final regex is: \b (?= \w {6} \b ) \w {0,3} cat \w * .
You could replace the final \w * with \w {0,3} too. But it wouldn't make any difference. The lookahead has already checked that we're at a 6-letter word, and \w {0,3} cat has already matched 3 to 6 letters of that word. Whether we end the regex with \w * or \w {0,3} doesn't matter, because either way, we'll be matching all the remaining word characters. Because the resulting match and the speed at which it is found are the same, we may just as well use the version that is easier to type.
So, what would you use to find any word between 6 and 12 letters long containing either "cat", "dog" or "mouse"? Again we have two requirements, which we can easily combine using a lookahead: \b (?= \w {6,12} \b ) \w {0,9} ( cat | dog | mouse ) \w * . Very easy, once you get the hang of it. This regex will also put "cat", "dog" or "mouse" into the first backreference.
Lookbehind is often used to match certain text that is preceded by other text, without including the other text in the overall regex match. (?<= h ) d matches only the second d in adhd . While a lot of regex flavors support lookbehind, most regex flavors only allow a subset of the regex syntax to be used inside lookbehind. Perl and Boost require the lookbehind to be of fixed length. PCRE and Ruby allow alternatives of different length, but still don't allow quantifiers other than the fixed-length {n} .
To overcome the limitations of lookbehind, Perl 5.10, PCRE 7.2, Ruby 2.0, and Boost 1.42 introduce a new feature that can be used instead of lookbehind for its most common purpose. keeps the text matched so far out of the overall regex match. h d matches only the second d in adhd .
The JGsoft flavor has always supported unrestricted lookbehind , which is much more flexible than . Still, JGsoft V2 adds support for if you prefer this way of working.
Let's see how h d works. The engine begins the match attempt at the start of the string. h fails to match a . There are no further alternatives to try. The match attempt at the start of the string has failed.
The engine advances one character through the string and attempts the match again. h fails to match d .
Advancing again, h matches h . The engine advances through the regex. The regex has now reached in the regex and the position between h and the second d in the string. does nothing other than to tell that if this match attempt ends up succeeding, the regex engine should pretend that the match attempt started at the present position between h and d , rather than between the first d and h where it really started.
The engine advances through the regex. d matches the second d in the string. An overall match is found. Because of the position saved by , the second d in the string is returned as the overall match.
only affects the position returned after a successful match. It does not move the start of the match attempt during the matching process. The regex hhh d matches the d in hhhhd . This regex first matches hhh at the start of the string. Then notes the position between hhh and hd in the string. Then d fails to match the fourth h in the string. The match attempt at the start of the string has failed.
Now the engine must advance one character in the string before starting the next match attempt. It advances from the actual start of the match attempt, which was at the start of the string. The position stored by does not change this. So the second match attempt begins at the position after the first h in the string. Starting there, hhh matches hhh , notes the position, and d matches d . Now, the position remembered by is taken into account, and d is returned as the overall match.
You can use pretty much anywhere in any regular expression. You should only avoid using it inside lookbehind. You can use it inside groups, even when they have quantifiers. You can have as many instances of in your regex as you like. ( ab c | d e ) f matches cf when preceded by ab . It also matches ef when preceded by d .
does not affect capturing groups. When ( ab c | d e ) f matches cf , the capturing group captures abc as if the weren't there. When the regex matches ef , the capturing group stores de .
Because does not affect the way the regex engine goes through the matching process, it offers a lot more flexibility than lookbehind in Perl, PCRE, and Ruby. You can put anything to the left of , but you're limited to what you can put inside lookbehind.
But this flexibility does come at a cost. Lookbehind really goes backwards through the string. This allows lookbehind check for a match before the start of the match attempt. When the match attempt was started at the end of the previous match, lookbehind can match text that was part of the previous match. cannot do this, precisely because it does not affect the way the regex engine goes through the matching process.
If you iterate over all matches of (?<= a ) a in the string aaaa , you will get three matches: the second, third, and fourth a in the string. The first match attempt begins at the start of the string and fails because the lookbehind fails. The second match attempt begins between the first and second a , where the lookbehind succeeds and the second a is matched. The third match attempt begins after the second a that was just matched. Here the lookbehind succeeds too. It doesn't matter that the preceding a was part of the previous match. Thus the third match attempt matches the third a . Similarly, the fourth match attempt matches the fourth a . The fifth match attempt starts at the end of the string. The lookbehind still succeeds, but there are no characters left for a to match. The match attempt fails. The engine has reached the end of the string and the iteration stops. Five match attempts have found three matches.
Things are different when you iterate over a a in the string aaaa . You will get only two matches: the second and the fourth a . The first match attempt begins at the start of the string. The first a in the regex matches the first a in the string. notes the position. The second a matches the second a in the string, which is returned as the first match. The second match attempt begins after the second a that was just matched. The first a in the regex matches the third a in the string. notes the position. The second a matches the fourth a in the string, which is returned as the first match. The third match attempt begins at the end of the string. a fails. The engine has reached the end of the string and the iteration stops. Three match attempts have found two matches.
Basically, you'll run into this issue when the part of the regex before the can match the same text as the part of the regex after the . If those parts can't match the same text, then a regex using will find the same matches than the same regex rewritten using lookbehind. In that case, you should use instead of lookbehind as that will give you better performance in Perl, PCRE, and Ruby.
Another limitation is that while lookbehind comes in positive and negative variants, does not provide a way to negate anything. (?<! a ) b matches the string b entirely, because it is a "b" not preceded by an "a". [ ^ a ] b does not match the string b at all. When attempting the match, [ ^ a ] matches b . The regex has now reached the end of the string. notes this position. But now there is nothing left for b to match. The match attempt fails. [ ^ a ] b is the same as (?<= [ ^ a ] ) b , which are both different from (?<! a ) b .
A special construct (?ifthen|else) allows you to create conditional regular expressions. If the if part evaluates to true, then the regex engine will attempt to match the then part. Otherwise, the else part is attempted instead. The syntax consists of a pair of parentheses. The opening bracket must be followed by a question mark, immediately followed by the if part, immediately followed by the then part. This part can be followed by a vertical bar and the else part. You may omit the else part, and the vertical bar with it.
For the if part, you can use the lookahead and lookbehind constructs. Using positive lookahead, the syntax becomes (? (?= regex ) then | else ) . Because the lookahead has its own parentheses, the if and then parts are clearly separated.
Remember that the lookaround constructs do not consume any characters. If you use a lookahead as the if part, then the regex engine will attempt to match the then or else part (depending on the outcome of the lookahead) at the same position where the if was attempted.
Alternatively, you can check in the if part whether a capturing group has taken part in the match thus far. Place the number of the capturing group inside parentheses, and use that as the if part. Note that although the syntax for a conditional check on a backreference is the same as a number inside a capturing group, no capturing group is created. The number and the parentheses are part of the if-then-else syntax started with (? .
For the then and else , you can use any regular expression. If you want to use alternation , you will have to group the then or else together using parentheses , like in (? (?= condition ) ( then1 | then2 | then3 ) | ( else1 | else2 | else3 ) ) . Otherwise, there is no need to use parentheses around the then and else parts.
The regex ( a ) ? b (?(1) c | d ) consists of the optional capturing group ( a ) ? , the literal b , and the conditional (?(1) c | d ) that tests the capturing group. This regex matches bd and abc . It does not match bc , but does match bd in abd . Let's see how this regular expression works on each of these four subject strings.
When applied to bd , a fails to match. Since the capturing group containing a is optional, the engine continues with b at the start of the subject string. Since the whole group was optional, the group did not take part in the match. Any subsequent backreference to it like \1 will fail. Note that ( a ) ? is very different from ( a ? ) . In the former regex, the capturing group does not take part in the match if a fails, and backreferences to the group will fail. In the latter group, the capturing group always takes part in the match, capturing either a or nothing. Backreferences to a capturing group that took part in the match and captured nothing always succeed. Conditionals evaluating such groups execute the "then" part. In short: if you want to use a reference to a group in a conditional, use ( a ) ? instead of ( a ? ) .
Continuing with our regex, b matches b . The regex engine now evaluates the conditional. The first capturing group did not take part in the match at all, so the "else" part or d is attempted. d matches d and an overall match is found.
Moving on to our second subject string abc , a matches a , which is captured by the capturing group. Subsequently, b matches b . The regex engine again evaluates the conditional. The capturing group took part in the match, so the "then" part or c is attempted. c matches c and an overall match is found.
Our third subject bc does not start with a , so the capturing group does not take part in the match attempt, like we saw with the first subject string. b still matches b , and the engine moves on to the conditional. The first capturing group did not take part in the match at all, so the "else" part or d is attempted. d does not match c and the match attempt at the start of the string fails. The engine does try again starting at the second character in the string, but fails since b does not match c .
The fourth subject abd is the most interesting one. Like in the second string, the capturing group grabs the a and the b matches. The capturing group took part in the match, so the "then" part or c is attempted. c fails to match d , and the match attempt fails. Note that the "else" part is not attempted at this point. The capturing group took part in the match, so only the "then" part is used. However, the regex engine isn't done yet. It restarts the regular expression from the beginning, moving ahead one character in the subject string.
Starting at the second character in the string, a fails to match b . The capturing group does not take part in the second match attempt which started at the second character in the string. The regex engine moves beyond the optional group, and attempts b , which matches. The regex engine now arrives at the conditional in the regex, and at the third character in the subject string. The first capturing group did not take part in the current match attempt, so the "else" part or d is attempted. d matches d and an overall match bd is found.
If you want to avoid this last match result, you need to use anchors . ^ ( a ) ? b (?(1) c | d ) $ does not find any matches in the last subject string. The caret fails to match before the second and third characters in the string.
Conditionals are supported by the JGsoft engine , Perl , PCRE , Python , and the .NET framework . Ruby supports them starting with version 2.0. Languages such as Delphi , PHP , and R that have regex features based on PCRE also support conditionals.
All these flavors also support named capturing groups . You can use the name of a capturing group instead of its number as the if test. The syntax is slightly inconsistent between regex flavors. In Python, .NET, and the JGsoft applications, you simply specify the name of the group between parentheses. (?<test> a ) ? b (?(test) c | d ) is the regex from the previous section using named capture. In Perl or Ruby, you have to put angle brackets or quotes around the name of the group, and put that between the conditional's parentheses: (?<test> a ) ? b (?(<test>) c | d ) or (?'test' a ) ? b (?('test') c | d ) . PCRE supports all three variants.
PCRE 7.2 and later and JGsoft V2 also support relative conditionals. The syntax is the same as that of a conditional that references a numbered capturing group with an added plus or minus sign before the group number. The conditional then counts the opening parentheses to the left (minus) or to the right (plus) starting at the (?( that opens the conditional. ( a ) ? b (?(-1) c | d ) is another way of writing the above regex. The benefit is that this regex won't break if you add capturing groups at the start or the end of the regex.
Python supports conditionals using a numbered or named capturing group. Python does not support conditionals using lookaround, even though Python does support lookaround outside conditionals. Instead of a conditional like (? (?= regex ) then | else ) , you can alternate two opposite lookarounds: (?= regex ) then | (?! regex ) else .
Boost and Ruby treat a conditional that references a non-existent capturing group as an error. The latest versions of all other flavors discussed in this tutorial don't. They simply let such conditionals always attempt the "else" part. A few flavors changed their minds, though. Python 3.4 and prior and PCRE 7.6 and prior (and thus PHP 5.2.5 and prior) used to treat them as errors.
The regex ^ ( ( From | To ) | Subject ) : ( (?(2) \w + @ \w + \. [ a - z ] + | . + ) ) extracts the From, To, and Subject headers from an email message. The name of the header is captured into the first backreference. If the header is the From or To header, it is captured into the second backreference as well.
The second part of the pattern is the if-then-else conditional (?(2) \w + @ \w + \. [ a - z ] + | . + ) ) . The if part checks whether the second capturing group took part in the match thus far. It will have taken part if the header is the From or To header. In that case, the then part of the conditional \w + @ \w + \. [ a - z ] + tries to match an email address . To keep the example simple, we use an overly simple regex to match the email address, and we don't try to match the display name that is usually also part of the From or To header.
If the second capturing group did not participate in the match this far, the else part . + is attempted instead. This simply matches the remainder of the line, allowing for any test subject.
Finally, we place an extra pair of parentheses around the conditional. This captures the contents of the email header matched by the conditional into the third backreference. The conditional itself does not capture anything. When implementing this regular expression, the first capturing group will store the name of the header ("From", "To", or "Subject"), and the third capturing group will store the value of the header.
You could try to match even more headers by putting another conditional into the "else" part. E.g. ^ ( ( From | To ) | ( Date ) | Subject ) : ( (?(2) \w + @ \w + \. [ a - z ] + | (?(3) mm/dd/yyyy | . + ) ) ) would match a "From", "To", "Date" or "Subject", and use the regex mm/dd/yyyy to check whether the date is valid . Obviously, the date validation regex is just a dummy to keep the example simple. The header is captured in the first group, and its validated contents in the fourth group.
As you can see, regular expressions using conditionals quickly become unwieldy. I recommend that you only use them if one regular expression is all your tool allows you to use. When programming, you're far better of using the regex ^ ( From | To | Date | Subject ) : ( . + ) to capture one header with its unvalidated contents. In your source code, check the name of the header returned in the first capturing group, and then use a second regular expression to validate the contents of the header returned in the second capturing group of the first regex. Though you'll have to write a few lines of extra code, this code will be much easier to understand and maintain. If you precompile all the regular expressions, using multiple regular expressions will be just as fast, if not faster, than the one big regex stuffed with conditionals.
The .NET regex flavor has a special feature called balancing groups. The main purpose of balancing groups is to match balanced constructs or nested constructs, which is where they get their name from. A technically more accurate name for the feature would be capturing group subtraction. That's what the feature really does. It's .NET's solution to a problem that other regex flavors like Perl , PCRE , and Ruby handle with regular expression recursion . JGsoft V2 supports both balancing groups and recursion.
(?<capture-subtract>regex) or (?'capture-subtract'regex) is the basic syntax of a balancing group. It's the same syntax used for named capturing groups in .NET but with two group names delimited by a minus sign. The name of this group is "capture". You can omit the name of the group. (?<-subtract>regex) or (?'-subtract'regex) is the syntax for a non-capturing balancing group.
The name "subtract" must be the name of another group in the regex. When the regex engine enters the balancing group, it subtracts one match from the group "subtract". If the group "subtract" did not match yet, or if all its matches were already subtracted, then the balancing group fails to match. You could think of a balancing group as a conditional that tests the group "subtract", with "regex" as the "if" part and an "else" part that always fails to match. The difference is that the balancing group has the added feature of subtracting one match from the group "subtract", while a conditional leaves the group untouched.
If the balancing group succeeds and it has a name ("capture" in this example), then the group captures the text between the end of the match that was subtracted from the group "subtract" and the start of the match of the balancing group itself ("regex" in this example).
The reason this works in .NET is that capturing groups in .NET keep a stack of everything they captured during the matching process that wasn't backtracked or subtracted. Most other regex engines only store the most recent match of each capturing groups. When ( \w ) + matches abc then Match.Groups[1].Value returns c as with other regex engines, but Match.Groups[1].Captures stores all three iterations of the group: a , b , and c .
Let's apply the regex (?'open' o ) + (?'between-open' c ) + to the string ooccc . (?'open' o ) matches the first o and stores that as the first capture of the group "open". The quantifier + repeats the group. (?'open' o ) matches the second o and stores that as the second capture. Repeating again, (?'open' o ) fails to match the first c . But the + is satisfied with two repetitions.
The regex engine advances to (?'between-open' c ) . Before the engine can enter this balancing group, it must check whether the subtracted group "open" has captured something. It has captured the second o . The engine enters the group, subtracting the most recent capture from "open". This leaves the group "open" with the first o as its only capture. Now inside the balancing group, c matches c . The engine exits the balancing group. The group "between" captures the text between the match subtracted from "open" (the second o ) and the c just matched by the balancing group. This is an empty string but it is captured anyway.
The balancing group too has + as its quantifier. The engine again finds that the subtracted group "open" captured something, namely the first o . The regex enters the balancing group, leaving the group "open" without any matches. c matches the second c in the string. The group "between" captures oc which is the text between the match subtracted from "open" (the first o ) and the second c just matched by the balancing group.
The balancing group is repeated again. But this time, the regex engine finds that the group "open" has no matches left. The balancing group fails to match. The group "between" is unaffected, retaining its most recent capture.
The + is satisfied with two iterations. The engine has reached the end of the regex. It returns oocc as the overall match. Match.Groups['open'].Success will return false , because all the captures of that group were subtracted. Match.Groups['between'].Value returns "oc" .
We need to modify this regex if we want it to match a balanced number of o's and c's. To make sure that the regex won't match ooccc , which has more c's than o's, we can add anchors : ^ (?'open' o ) + (?'-open' c ) + $ . This regex goes through the same matching process as the previous one. But after (?'-open' c ) + fails to match its third iteration, the engine reaches $ instead of the end of the regex. This fails to match. The regex engine will backtrack trying different permutations of the quantifiers, but they will all fail to match. No match can be found.
But the regex ^ (?'open' o ) + (?'-open' c ) + $ still matches ooc . The matching process is again the same until the balancing group has matched the first c and left the group 'open' with the first o as its only capture. The quantifier makes the engine attempt the balancing group again. The engine again finds that the subtracted group "open" captured something. The regex enters the balancing group, leaving the group "open" without any matches. But now, c fails to match because the regex engine has reached the end of the string.
The regex engine must now backtrack out of the balancing group. When backtracking a balancing group, .NET also backtracks the subtraction. Since the capture of the the first o was subtracted from "open" when entering the balancing group, this capture is now restored while backtracking out of the balancing group. The repeated group (?'-open' c ) + is now reduced to a single iteration. But the quantifier is fine with that, as + means "once or more" as it always does. Still at the end of the string, the regex engine reaches $ in the regex, which matches. The whole string ooc is returned as the overall match. Match.Groups['open'].Captures will hold the first o in the string as the only item in the CaptureCollection. That's because, after backtracking, the second o was subtracted from the group, but the first o was not.
To make sure the regex matches oc and oocc but not ooc , we need to check that the group "open" has no captures left when the matching process reaches the end of the regex. We can do this with a conditional . (?(open) (?!) ) is a conditional that checks whether the group "open" matched something. In .NET, having matched something means still having captures on the stack that weren't backtracked or subtracted. If the group has captured something, the "if" part of the conditional is evaluated. In this case that is the empty negative lookahead (?!) . The empty string inside this lookahead always matches. Because the lookahead is negative, this causes the lookahead to always fail. Thus the conditional always fails if the group has captured something. If the group has not captured anything, the "else" part of the conditional is evaluated. In this case there is no "else" part. This means that the conditional always succeeds if the group has not captured something. This makes (?(open) (?!) ) a proper test to verify that the group "open" has no captures left.
The regex ^ (?'open' o ) + (?'-open' c ) + (?(open) (?!) ) $ fails to match ooc . When c fails to match because the regex engine has reached the end of the string, the engine backtracks out of the balancing group, leaving "open" with a single capture. The regex engine now reaches the conditional, which fails to match. The regex engine will backtrack trying different permutations of the quantifiers, but they will all fail to match. No match can be found.
The regex ^ (?'open' o ) + (?'-open' c ) + (?(open) (?!) ) $ does match oocc . After (?'-open' c ) + has matched cc , the regex engine cannot enter the balancing group a third time, because "open" has no captures left. The engine advances to the conditional. The conditional succeeds because "open" has no captures left and the conditional does not have an "else" part. Now $ matches at the end of the string.
^ (?: (?'open' o ) + (?'-open' c ) + ) + (?(open) (?!) ) $ wraps the capturing group and the balancing group in a non-capturing group that is also repeated. This regex matches any string like ooocooccocccoc that contains any number of perfectly balanced o's and c's, with any number of pairs in sequence, nested to any depth. The balancing group makes sure that the regex never matches a string that has more c's at any point in the string than it has o's to the left of that point. The conditional at the end, which must remain outside the repeated group, makes sure that the regex never matches a string that has more o's than c's.
^ (?> (?'open' o ) + (?'-open' c ) + ) + (?(open) (?!) ) $ optimizes the previous regex by using an atomic group instead of the non-capturing group. The atomic group, which is also non-capturing, eliminates nearly all backtracking when the regular expression cannot find a match, which can greatly increase performance when used on long strings with lots of o's and c's but that aren't properly balanced at the end. The atomic group does not change how the regex matches strings that do have balanced o's and c's.
^ m * (?> (?> (?'open' o ) m * ) + (?> (?'-open' c ) m * ) + ) + (?(open) (?!) ) $ allows any number of letters m anywhere in the string, while still requiring all o's and c's to be balanced. m * at the start of the regex allows any number of m's before the first o. (?'open' o ) + was changed into (?> (?'open' o ) m * ) + to allow any number of m's after each o. Similarly, (?'-open' c ) + was changed into (?> (?'-open' c ) m * ) + to allow any number of m's after each c.
This is the generic solution for matching balanced constructs using .NET's balancing groups or capturing group subtraction feature. You can replace o , m , and c with any regular expression, as long as no two of these three can match the same text.
^ [ ^ () ] * (?> (?> (?'open' \( ) [ ^ () ] * ) + (?> (?'-open' \) ) [ ^ () ] * ) + ) + (?(open) (?!) ) $ applies this technique to match a string in which all parentheses are perfectly balanced.
You can use backreferences to groups that have their matches subtracted by a balancing group. The backreference matches the group's most recent match that wasn't backtracked or subtracted. The regex (?'x' [ ab ] ) {2} (?'-x') \k'x' matches aaa , aba , bab , or bbb . It does not match aab , abb , baa , or bba . The first and third letters of the string have to be the same.
Let's see how (?'x' [ ab ] ) {2} (?'-x') \k'x' matches aba . The first iteration of (?'x' [ ab ] ) captures a . The second iteration captures b . Now the regex engine reaches the balancing group (?'-x') . It checks whether the group "x" has matched, which it has. The engine enters the balancing group, subtracting the match b from the stack of group "x". There are no regex tokens inside the balancing group. It matches without advancing through the string. Now the regex engine reaches the backreference \k'x' . The match at the top of the stack of group "x" is a . The next character in the string is also an a which the backreference matches. aba is found as an overall match.
When you apply this regex to abb , the matching process is the same, except that the backreference fails to match the second b in the string. Since the regex has no other permutations that the regex engine can try, the match attempt fails.
^ (?'letter' [ a - z ] ) + [ a - z ] ? (?: \k'letter' (?'-letter') ) + (?(letter) (?!) ) $ matches palindrome words of any length. This regular expression takes advantage of the fact that backreferences and capturing group subtraction work well together. It also uses an empty balancing group as the regex in the previous section.
Let's see how this regex matches the palindrome radar . ^ matches at the start of the string. Then (?'letter' [ a - z ] ) + iterates five times. The group "letter" ends up with five matches on its stack: r , a , d , a , and r . The regex engine is now at the end of the string and at [ a - z ] ? in the regex. It doesn't match, but that's fine, because the quantifier makes it optional. The engine now reaches the backreference \k'letter' . The group "letter" has r at the top of its stack. This fails to match the void after the end of the string.
The regex engine backtracks. (?'letter' [ a - z ] ) + is reduced to four iterations, leaving r , a , d , and a on the stack of the group "letter". [ a - z ] ? matches r . The backreference again fails to match the void after the end of the string. The engine backtracks, forcing [ a - z ] ? to give up its match. Now "letter" has a at the top of its stack. This causes the backreference to fail to match r .
More backtracking follows. (?'letter' [ a - z ] ) + is reduced to three iterations, leaving d at the top of the stack of the group "letter". The engine again proceeds with [ a - z ] ? . It fails again because there is no d for the backreference to match.
Backtracking once more, the capturing stack of group "letter" is reduced to r and a . Now the tide turns. [ a - z ] ? matches d . The backreference matches a which is the most recent match of the group "letter" that wasn't backtracked. The engine now reaches the empty balancing group (?'-letter') . This matches, because the group "letter" has a match a to subtract.
The backreference and balancing group are inside a repeated non-capturing group, so the engine tries them again. The backreference matches r and the balancing group subtracts it from "letter"'s stack, leaving the capturing group without any matches. Iterating once more, the backreference fails, because the group "letter" has no matches left on its stack. This makes the group act as a non-participating group. Backreferences to non-participating groups always fail in .NET, as they do in most regex flavors.
(?: \k'letter' (?'-letter') ) + has successfully matched two iterations. Now, the conditional (?(letter) (?!) ) succeeds because the group "letter" has no matches left. The anchor $ also matches. The palindrome radar has been matched.
Perl 5.10 , PCRE 4.0 , Ruby 2.0 , and all later versions of these three, support regular expression recursion. Perl uses the syntax (?R) with (?0) as a synonym. Ruby 2.0 uses \g<0> . PCRE supports all three as of version 7.7. Earlier versions supported only the Perl syntax (which Perl actually copied from PCRE). Recent versions of Delphi , PHP , and R also support all three, as their regex functions are based on PCRE. JGsoft V2 also supports all variations of regex recursion.
While Ruby 1.9 does not have any syntax for regex recursion, it does support capturing group recursion . So you could recurse the whole regex in Ruby 1.9 if you wrap the whole regex in a capturing group. .NET does not support recursion, but it supports balancing groups that can be used instead of recursion to match balanced constructs.
As we'll see later, there are differences in how Perl, PCRE, and Ruby deal with backreferences and backtracking during recursion. While they copied each other's syntax, they did not copy each other's behavior. JGsoft V2, however, copied their syntax and their behavior. So JGsoft V2 has three different ways of doing regex recursion, which you choose by using a different syntax. But these differences do not come into play in the basic example on this page.
Boost 1.42 copied the syntax from Perl. But its implementation is marred by bugs. Boost 1.60 attempted to fix the behavior of quantifiers on recursion , but it's still quite different from other flavors and incompatible with previous versions of Boost. Boost 1.64 finally stopped crashing upon infinite recursion . But recursion of the whole regex still attempts only the first alternative.
The regexes a (?R) ? z , a (?0) ? z , and a \g<0> ? z all match one or more letters a followed by exactly the same number of letters z . Since these regexes are functionally identical, we'll use the syntax with R for recursion to see how this regex matches the string aaazzz .
First, a matches the first a in the string. Then the regex engine reaches (?R) . This tells the engine to attempt the whole regex again at the present position in the string. Now, a matches the second a in the string. The engine reaches (?R) again. On the second recursion, a matches the third a . On the third recursion, a fails to match the first z in the string. This causes (?R) to fail. But the regex uses a quantifier to make (?R) optional . So the engine continues with z which matches the first z in the string.
Now, the regex engine has reached the end of the regex. But since it's two levels deep in recursion, it hasn't found an overall match yet. It only has found a match for (?R) . Exiting the recursion after a successful match, the engine also reaches z . It now matches the second z in the string. The engine is still one level deep in recursion, from which it exists with a successful match. Finally, z matches the third z in the string. The engine is again at the end of the regex. This time, it's not inside any recursion. Thus, it returns aaazzz as the overall regex match.
The main purpose of recursion is to match balanced constructs or nested constructs. The generic regex is b (?: m | (?R) ) * e where b is what begins the construct, m is what can occur in the middle of the construct, and e is what can occur at the end of the construct. For correct results, no two of b , m , and e should be able to match the same text. You can use an atomic group instead of the non-capturing group for improved performance: b (?> m | (?R) ) * e .
A common real-world use is to match a balanced set of parentheses. \( (?> [ ^ () ] | (?R) ) * \) matches a single pair of parentheses with any text in between, including an unlimited number of parentheses, as long as they are all properly paired. If the subject string contains unbalanced parentheses, then the first regex match is the leftmost pair of balanced parentheses, which may occur after unbalanced opening parentheses. If you want a regex that does not find any matches in a string that contains unbalanced parentheses, then you need to use a subroutine call instead of recursion. If you want to find a sequence of multiple pairs of balanced parentheses as a single match, then you also need a subroutine call.
If what may appear in the middle of the balanced construct may also appear on its own without the beginning and ending parts then the generic regex is b (?R) * e | m . Again, b , m , and e all need to be mutually exclusive. \( (?R) * \) | [ ^ () ] + matches a pair of balanced parentheses like the regex in the previous section. But it also matches any text that does not contain any parentheses at all.
This regular expression does not work correctly in Boost. If a regex has alternation that is not inside a group then recursion of the whole regex in Boost only attempts the first alternative. So \( (?R) * \) | [ ^ () ] + in Boost matches any number of balanced parentheses nested arbitrarily deep with no text in between, or any text that does not contain any parentheses at all. If you flip the alternatives then [ ^ () ] + | \( (?R) * \) in Boost matches any text without any parentheses or a single pair of parentheses with any text without parentheses in between. In all other flavors these two regexes find the same matches.
The solution for Boost is to put the alternation inside a group. (?: \( (?R) * \) | [ ^ () ] + ) and (?: [ ^ () ] + | \( (?R) * \) ) find the same matches in all flavors discussed in this tutorial that support recursion.
Perl 5.10 , PCRE 4.0 , and Ruby 1.9 support regular expression subroutine calls. These are very similar to regular expression recursion . Instead of matching the entire regular expression again, a subroutine call only matches the regular expression inside a capturing group. You can make a subroutine call to any capturing group from anywhere in the regex. If you place a call inside the group that it calls, you'll have a recursive capturing group.
As with regex recursion, there is a wide variety of syntax that you can use for exactly the same thing. Perl uses (?1) to call a numbered group, (?+1) to call the next group, (?-1) to call the preceding group, and (?&name) to call a named group. You can use all of these to reference the same group. (?+1) (?'name' [ abc ] ) (?1) (?-1) (?&name) matches a string that is five letters long and consists only of the first three letters of the alphabet. This regex is exactly the same as [ abc ] (?'name' [ abc ] ) [ abc ] [ abc ] [ abc ] .
PCRE was the first regex engine to support subroutine calls. (?P<name> [ abc ] ) (?1) (?P>name) matches three letters like (?P<name> [ abc ] ) [ abc ] [ abc ] does. (?1) is a call to a numbered group and (?P>name) is a call to a named group. The latter is called the "Python syntax" in the PCRE man page. While this syntax mimics the syntax Python uses for named capturing groups , it is a PCRE invention. Python does not support subroutine calls or recursion. PCRE 7.2 added (?+1) and (?-1) for relative calls. PCRE 7.7 adds all the syntax used by Perl 5.10 and Ruby 2.0. Recent versions of PHP , Delphi , and R also support all this syntax, as their regex functions are based on PCRE.
The syntax used by Ruby 1.9 and later looks more like that of backreferences. \g<1> and \g'1' call a numbered group, \g<name> and \g'name' call a named group, while \g<-1> and \g'-1' call the preceding group. Ruby 2.0 adds \g<+1> and \g'+1' to call the next group. \g<+1> (?<name> [ abc ] ) \g<1> \g<-1> \g<name> and \g'+1' (?'name' [ abc ] ) \g'1' \g'-1' \g'name' match the same 5-letter string in Ruby 2.0 as the Perl example does in Perl. The syntax with angle brackets and with quotes can be used interchangeably.
JGsoft V2 supports all three sets of syntax. As we'll see later, there are differences in how Perl, PCRE, and Ruby deal with capturing , backreferences , and backtracking during subroutine calls. While they copied each other's syntax, they did not copy each other's behavior. JGsoft V2, however, copied their syntax and their behavior. So JGsoft V2 has three different ways of doing regex recursion, which you choose by using a different syntax. But these differences do not come into play in the basic examples on this page.
Boost 1.42 copied the syntax from Perl but its implementation is marred by bugs, which are still not all fixed in version 1.62. Most significantly, quantifiers other than * or {0,} cause subroutine calls to misbehave. This is partially fixed in Boost 1.60 which correctly handles ? and {0,1} too.
Boost does not support the Ruby syntax for subroutine calls. In Boost \g<1> is a backreference—not a subroutine call—to capturing group 1. So ( [ ab ] ) \g<1> can match aa and bb but not ab or ba . In Ruby the same regex would match all four strings. No other flavor discussed in this tutorial uses this syntax for backreferences.
Recursion into a capturing group is a more flexible way of matching balanced constructs than recursion of the whole regex. We can wrap the regex in a capturing group, recurse into the capturing group instead of the whole regex, and add anchors outside the capturing group. \A ( b (?: m | (?1) ) * e ) \z is the generic regex for checking that a string consists entirely of a correctly balanced construct. Again, b is what begins the construct, m is what can occur in the middle of the construct, and e is what can occur at the end of the construct. For correct results, no two of b , m , and e should be able to match the same text. You can use an atomic group instead of the non-capturing group for improved performance: \A ( b (?> m | (?1) ) * e ) \z .
Similarly, \A o * ( b (?: m | (?1) ) * e o * ) + \z and the optimized \A o * + ( b (?> m | (?1) ) * + e o * + ) + + \z match a string that consists of nothing but a sequence of one or more correctly balanced constructs, with possibly other text in between. Here, o is what can occur outside the balanced constructs. It will often be the same as m . o should not be able to match the same text as b or e .
\A ( \( (?> [ ^ () ] | (?1) ) * \) ) \z matches a string that consists of nothing but a correctly balanced pair of parentheses, possibly with text between them. \A [ ^ () ] * + ( \( (?> [ ^ () ] | (?1) ) * + \) [ ^ () ] * + ) + + \z .
A regex that needs to match the same kind of construct (but not the exact same text) more than once in different parts of the regex can be shorter and more concise when using subroutine calls. Suppose you need a regex to match patient records like these:
Name: John Doe Born: 17-Jan-1964 Admitted: 30-Jul-2013 Released: 3-Aug-2013
Further suppose that you need to match the date format rather accurately so the regex can filter out valid records, leaving invalid records for human inspection. In most regex flavors you could easily do this with this regex, using free-spacing syntax :
^
Name:
\
(
.
*
)
\r
?
\n
Born:
\
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
\r
?
\n
Admitted:
\
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
\r
?
\n
Released:
\
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
$
With subroutine calls you can make this regex much shorter, easier to read, and easier to maintain:
^
Name:
\
(
.
*
)
\r
?
\n
Born:
\
(?'date'
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
)
\r
?
\n
Admitted:
\
\g'date'
\r
?
\n
Released:
\
\g'date'
$
In Perl, PCRE, and JGsoft V2, you can take this one step further using the special DEFINE group: (?(DEFINE) (?'subroutine' regex ) ) . While this looks like a conditional that references the non-existent group DEFINE containing a single named group "subroutine", the DEFINE group is a special syntax. The fixed text (?(DEFINE) opens the group. A parenthesis closes the group. This special group tells the regex engine to ignore its contents, other than to parse it for named and numbered capturing groups. You can put as many capturing groups inside the DEFINE group as you like. The DEFINE group itself never matches anything, and never fails to match. It is completely ignored. The regex foo (?(DEFINE) (?'subroutine' skipped ) ) bar matches foobar . The DEFINE group is completely superfluous in this regex, as there are no calls to any of the groups inside of it.
With a DEFINE group, our regex becomes:
(?(DEFINE)
(?'date'
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
)
)
^
Name:
\
(
.
*
)
\r
?
\n
Born:
\
(?P>date)
\r
?
\n
Admitted:
\
(?P>date)
\r
?
\n
Released:
\
(?P>date)
$
Quantifiers on subroutine calls work just like a quantifier on recursion . The call is repeated as many times in sequence as needed to satisfy the quantifier. ( [ abc ] ) (?1) {3} matches abcb and any other combination of four-letter combination of the first three letters of the alphabet. First the group matches once, and then the call matches three times. This regex is equivalent to ( [ abc ] ) [ abc ] {3} .
Quantifiers on the group are ignored by the subroutine call. ( [ abc ] ) {3} (?1) also matches abcb . First, the group matches three times, because it has a quantifier. Then the subroutine call matches once, because it has no quantifier. ( [ abc ] ) {3} (?1) {3} matches six letters, such as abbcab , because now both the group and the call are repeated 3 times. These two regexes are equivalent to ( [ abc ] ) {3} [ abc ] and ( [ abc ] ) {3} [ abc ] {3} .
While Ruby does not support subroutine definition groups, it does support subroutine calls to groups that are repeated zero times. ( a ) {0} \g<1> {3} matches aaa . The group itself is skipped because it is repeated zero times. Then the subroutine call matches three times, according to its quantifier. This also works in PCRE 7.7 and later. It doesn't work (reliably) in older versions of PCRE or in any version of Perl because of bugs.
The Ruby version of the patient record example can be further cleaned up as:
(?'date'
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
)
{0}
^
Name:
\
(
.
*
)
\r
?
\n
Born:
\
\g'date'
\r
?
\n
Admitted:
\
\g'date'
\r
?
\n
Released:
\
\g'date'
$
Regular expressions such as (?R) ? z or a ? (?R) ? z or a | (?R) z that use recursion without having anything that must be matched in front of the recursion can result in infinite recursion. If the regex engine reaches the recursion without having advanced through the text then the next recursion will again reach the recursion without having advanced through the text. With the first regex this happens immediately at the start of the match attempt. With the other two this happens as soon as there are no further letters a to be matched.
JGsoft V2 and Boost 1.64 treat the first two regexes as a syntax error because they always lead to infinite recursion. They allow the third regex because that one can match a . Ruby 1.9 and later, all versions of PCRE, and PCRE2 10.20 and prior treat all three forms of potential infinite recursion as a syntax error. Perl, PCRE2 10.21 and later, and Boost 1.63 and prior allow all three forms.
Subroutine calls can also lead to infinite recursion. All flavors handle the potentially infinite recursion in ( (?1) ? z ) or ( a ? (?1) ? z ) or ( a | (?1) z ) in the same way as they handle potentially infinite recursion of the entire regex.
But subroutine calls that are not recursive by themselves may end up being recursive if the group they call has another subroutine call that calls a parent group of the first subroutine call. When subroutine calls are forced to go around in a circle that too leads to infinite recursion. Detecting such circular calls when compiling a regex is more complicated than checking for straight infinite recursion. Only JGsoft V2 and Ruby 1.9 and later are able to detect this and treat it as a syntax error. All other flavors allow these regexes.
When infinite recursion does occur, whether it's straight recursion or subroutine calls going in circles, JGsoft V2, Perl, and PCRE2 treat it as a matching error that aborts the entire match attempt. Boost 1.64 handles this by not attempting the recursion and acting as if the recursion failed. If the recursion is optional then Boost 1.64 may find matches where other flavors throw errors.
Boost 1.63 and prior and PCRE 8.12 and prior crash when infinite recursion occurs. This also affects Delphi up to version XE6 and PHP up to version 5.4.8 as they are based on older PCRE versions.
A regex such as a (?R) z that has a recursion token that is not optional and is not have an alternative without the same recursion leads to endless recursion. Such a regular expression can never find a match. When a matches the regex engine attempts the recursion. If it can match another a then it has to attempt the recursion again. Eventually a will run out of letters to match. The recursion then fails. Because it's not optional the regex fails to match.
JGsoft V2 and Ruby detect this situation when compiling your regular expression. They flag endless recursion as a syntax error. Perl, PCRE, PCRE2, and Boost do not detect endless recursion. They simply go through the matching process which finds no matches.
The introduction to recursion shows how a (?R) ? z matches aaazzz . The quantifier ? makes the preceding token optional. In other words, it repeats the token between zero or one times. In a (?R) ? z the (?R) is made optional by the ? that follows it. You may wonder why the regex attempted the recursion three times, instead of once or not at all.
The reason is that upon recursion, the regex engine takes a fresh start in attempting the whole regex. All quantifiers and alternatives behave as if the matching process prior to the recursion had never happened at all, other than that the engine advanced through the string. The regex engine restores the states of all quantifiers and alternatives when it exits from a recursion, whether the recursion matched or failed. Basically, the matching process continues normally as if the recursion never happened, other than that the engine advanced through the string.
If you're familiar with procedural programming languages, regex recursion is basically a recursive function call and the quantifiers are local variables in the function. Each recursion of the function gets its own set of local variables that don't affect and aren't affected by the same local variables in recursions higher up the stack. Quantifiers on recursion work this way in all flavors, except Boost .
Let's see how a (?R) {3} z | q behaves (Boost excepted). The simplest possible match is q , found by the second alternative in the regex.
The simplest match in which the first alternative matches is aqqqz . After a is matches, the regex engine begins a recursion. a fails to match q . Still inside the recursion, the engine attempts the second alternative. q matches q . The engine exits from the recursion with a successful match. The engine now notes that the quantifier {3} has successfully repeated once. It needs two more repetitions, so the engine begins another recursion. It again matches q . On the third iteration of the quantifier, the third recursion matches q . Finally, z matches z and an overall match is found.
This regex does not match aqqz or aqqqqz . aqqz fails because during the third iteration of the quantifier, the recursion fails to match z . aqqqqz fails because after a (?R) {3} has matched aqqq , z fails to match the fourth q .
The regex can match longer strings such as aqaqqqzqz . With this string, during the second iteration of the quantifier, the recursion matches aqqqz . Since each recursion tracks the quantifier separately, the recursion needs three consecutive recursions of its own to satisfy its own instance of the quantifier. This can lead to arbitrarily long matches such as aaaqqaqqqzzaqqqzqzqaqqaaqqqzqqzzz .
Boost has its own ideas about how quantifiers should work on recursion. Recursion only works the same in Boost as in other flavors if the recursion operator either has no quantifier at all or if it has * as its quantifier. Any other quantifier may lead to very different matches (or lack thereof) in Boost 1.59 or prior versus Boost 1.60 and later versus other regex flavors. Boost 1.60 attempted to fix some of the differences between Boost and other flavors but it only resulted in a different incompatible behavior.
In Boost 1.59 and prior, quantifiers on recursion count both iteration and recursion throughout the entire recursion stack. So possible matches for a (?R) {3} z | q in Boost 1.59 include aaaazzzz , aaaqzzz , aaqqzz , aaqzqz , and aqaqzzz . In all these matches the number of recursions and iterations add up to 3. No other flavor would find these matches because they require 3 iterations during each recursion. So other flavors can match things like aaqqqzaqqqzaqqqzz or aqqaqqqzz . Boost 1.59 would match only aqqqz within these strings.
Boost 1.60 attempts to iterate quantifiers at each recursion level like other flavors, but does so incorrectly. Any quantifier that makes the recursion optional allows for infinite repetition. So Boost 1.60 and later treat a (?R) ? z the same as a (?R) * z . While this fixes the problem that a (?R) ? z could not match aaazzz entirely in Boost 1.59, it also allows matches such as aazazz that other flavors won't find with this regex. If the quantifier is not optional, then Boost 1.60 only allows it to match during the first recursion. So a (?R) {3} z | q could only ever match q or aqqqz .
Boost's issues with quantifiers on recursion also affect quantifiers on parent groups of the recursion token. They also affect quantifiers on subroutine calls and quantifiers groups that contain a subroutine call to a parent group of the group with the quantifier.
Quantifiers on other tokens in the regex behave normally during recursion. They track their iterations separately at each recursion. So a {2} (?R) z | q matches aaqz , aaaaqzz , aaaaaaqzzz , and so on. a has to match twice during each recursion.
Quantifiers like these that are inside the recursion but do not repeat the recursion itself do work correctly in Boost.
This tutorial introduced regular expression subroutines with this example that we want to match accurately:
Name: John Doe Born: 17-Jan-1964 Admitted: 30-Jul-2013 Released: 3-Aug-2013
In Ruby or PCRE , we can use this regular expression:
^
Name:
\
(
.
*
)
\n
Born:
\
(?'date'
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
)
\n
Admitted:
\
\g'date'
\n
Released:
\
\g'date'
$
Perl needs slightly different syntax, which also works in PCRE:
^
Name:
\
(
.
*
)
\n
Born:
\
(?'date'
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
)
\n
Admitted:
\
(?&date)
\n
Released:
\
(?&date)
$
Unfortunately, there are differences in how these three regex flavors treat subroutine calls beyond their syntax. First of all, in Ruby a subroutine call makes the capturing group store the text matched during the subroutine call. In Perl, PCRE, and Boost a subroutine call does not affect the group that is called.
When the Ruby solution matches the sample above, retrieving the contents of the capturing group "date" will get you 3-Aug-2013 which was matched by the last subroutine call to that group. When the Perl solution matches the same, retrieving $+{date} will get you 17-Jan-1964 . In Perl, the subroutine calls did not capture anything at all. But the "Born" date was matched with a normal named capturing group which stored the text that it matched normally. Any subroutine calls to the group don't change that. PCRE behaves as Perl in this case, even when you use the Ruby syntax with PCRE.
JGsoft V2 behaves like Ruby when you use the first regular expression. You can remember this by the fact that the \g syntax is a Ruby invention, later copied by PCRE. JGsoft V2 behaves like Perl when you use the second regular expression. You can remember this by the fact that Perl uses ampersands for subroutine calls in procedural code too.
If you want to extract the dates from the match, the best solution is to add another capturing group for each date. Then you can ignore the text stored by the "date" group and this particular difference between these flavors. In Ruby or PCRE:
^
Name:
\
(
.
*
)
\n
Born:
\
(?'born'
(?'date'
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
)
)
\n
Admitted:
\
(?'admitted'
\g'date'
)
\n
Released:
\
(?'released'
\g'date'
)
$
Perl needs slightly different syntax, which also works in PCRE:
^
Name:
\
(
.
*
)
\n
Born:
\
(?'born'
(?'date'
(?:
3
[
01
]
|
[
12
]
[
0
-
9
]
|
[
1
-
9
]
)
-
(?:
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
)
-
(?:
19
|
20
)
[
0
-
9
]
[
0
-
9
]
)
)
\n
Admitted:
\
(?'admitted'
(?&date)
)
\n
Released:
\
(?'released'
(?&date)
)
$
There are further differences between Perl, PCRE, and Ruby when your regex makes a subroutine call or recursive call to a capturing group that contains other capturing groups. The same issues also affect recursion of the whole regular expression if it contains any capturing groups. For the remainder of this topic, the term "recursion" applies equally to recursion of the whole regex, recursion into a capturing group, or a subroutine call to a capturing group.
PCRE and Boost back up and restores capturing groups when entering and exiting recursion. When the regex engine enters recursion, it internally makes a copy of all capturing groups. This does not affect the capturing groups. Backreferences inside the recursion match text captured prior to the recursion unless and until the group they reference captures something during the recursion. After the recursion, all capturing groups are replaced with the internal copy that was made at the start of the recursion. Text captured during the recursion is discarded. This means you cannot use capturing groups to retrieve parts of the text that were matched during recursion.
Perl 5.10, the first version to have recursion, through version 5.18, isolated capturing groups between each level of recursion. When Perl 5.10's regex engine enters recursion, all capturing groups appear as they have not participated in the match yet. Initially, all backreferences will fail. During the recursion, capturing groups capture as normal. Backreferences match text captured during the same recursion as normal. When the regex engine exits from the recursion, all capturing groups revert to the state they were in prior to the recursion. Perl 5.20 changed Perl's behavior to back up and restore capturing groups the way PCRE does.
For most practical purposes, however, you'll only use backreferences after their corresponding capturing groups. Then the difference between the way Perl 5.10 through 5.18 deal with capturing groups during recursion and the way PCRE and later versions of Perl do is academic.
Ruby's behavior is completely different. When Ruby's regex engine enters or exists recursion, it makes no changes to the text stored by capturing groups at all. Backreferences match the text stored by the capturing group during the group's most recent match, irrespective of any recursion that may have happened. After an overall match is found, each capturing group still stores the text of its most recent match, even if that was during a recursion. This means you can use capturing groups to retrieve part of the text matched during the last recursion.
JGsoft V2 behaves like Ruby when you use the \g syntax borrowed from Ruby. It behaves like Perl 5.20 and PCRE when you use any other syntax.
In Perl and PCRE you can use \b (?'word' (?'letter' [ a - z ] ) (?&word) \k'letter' | [ a - z ] ) \b to match palindrome words such as a , dad , radar , racecar , and redivider . This regex only matches palindrome words that are an odd number of letters long. This covers most palindrome words in English. To extend the regex to also handle palindrome words that are an even number of characters long we have to worry about differences in how Perl and PCRE backtrack after a failed recursion attempt which is discussed later in this tutorial. We gloss over these differences here because they only come into play when the subject string is not a palindrome and no match can be found.
Let's see how this regex matches radar . The word boundary \b matches at the start of the string. The regex engine enters the two capturing groups. [ a - z ] matches r which is then stored in the capturing group "letter". Now the regex engine enters the first recursion of the group "word". At this point, Perl forgets that the "letter" group matched r . PCRE does not. But this does not matter. (?'letter' [ a - z ] ) matches and captures a . The regex enters the second recursion of the group "word". (?'letter' [ a - z ] ) captures d . During the next two recursions, the group captures a and r . The fifth recursion fails because there are no characters left in the string for [ a - z ] to match. The regex engine must backtrack.
Because (?&word) failed to match, (?'letter' [ a - z ] ) must give up its match. The group reverts to a , which was the text the group held at the start of the recursion. (It becomes empty in Perl 5.18 and prior.) Again, this does not matter because the regex engine must now try the second alternative inside the group "word", which contains no backreferences. The second [ a - z ] matches the final r in the string. The engine now exits from a successful recursion. The text stored by the group "letter" is restored to what it had captured prior to entering the fourth recursion, which is a .
After matching (?&word) the engine reaches \k'letter' . The backreference fails because the regex engine has already reached the end of the subject string. So it backtracks once more, making the capturing group give up the a . The second alternative now matches the a . The regex engine exits from the third recursion. The group "letter" is restored to the d matched during the second recursion.
The regex engine has again matched (?&word) . The backreference fails again because the group stores d while the next character in the string is r . Backtracking again, the second alternative matches d and the group is restored to the a matched during the first recursion.
Now, \k'letter' matches the second a in the string. That's because the regex engine has arrived back at the first recursion during which the capturing group matched the first a . The regex engine exits the first recursion. The capturing group to the r which it matched prior to the first recursion.
Finally, the backreference matches the second r . Since the engine is not inside any recursion any more, it proceeds with the remainder of the regex after the group. \b matches at the end of the string. The end of the regex is reached and radar is returned as the overall match. If you query the groups "word" and "letter" after the match you'll get radar and r . That's the text matched by these groups outside of all recursion.
To match palindromes this way in Ruby, you need to use a special backreference that specifies a recursion level . If you use a normal backreference as in \b (?'word' (?'letter' [ a - z ] ) \g'word' \k'letter' | [ a - z ] ) \b , Ruby will not complain. But it will not match palindromes longer than three letters either. Instead this regex matches things like a , dad , radaa , raceccc , and rediviiii .
Let's see why this regex does not match radar in Ruby. Ruby starts out like Perl and PCRE, entering the recursions until there are no characters left in the string for [ a - z ] to match.
Because \g'word' failed to match, (?'letter' [ a - z ] ) must give up its match. Ruby reverts it to a , which was the text the group most recently matched. The second [ a - z ] matches the final r in the string. The engine now exits from a successful recursion. The group "letter" continues to hold its most recent match a .
After matching \g'word' the engine reaches \k'letter' . The backreference fails because the regex engine has already reached the end of the subject string. So it backtracks once more, reverting the group to the previously matched d . The second alternative now matches the a . The regex engine exits from the third recursion.
The regex engine has again matched \g'word' . The backreference fails again because the group stores d while the next character in the string is r . Backtracking again, the group reverts to a and the second alternative matches d .
Now, \k'letter' matches the second a in the string. The regex engine exits the first recursion which successfully matched ada . The capturing group continues to hold a which is its most recent match that wasn't backtracked.
The regex engine is now at the last character in the string. This character is r . The backreference fails because the group still holds a . The engine can backtrack once more, forcing (?'letter' [ a - z ] ) \g'word' \k'letter' to give up the rada it matched so far. The regex engine is now back at the start of the string. It can still try the second alternative in the group. This matches the first r in the string. Since the engine is not inside any recursion any more, it proceeds with the remainder of the regex after the group. \b fails to match after the first r . The regex engine has no further permutations to try. The match attempt has failed.
If the subject string is radaa , Ruby's engine goes through nearly the same matching process as described above. Only the events described in the last paragraph change. When the regex engine reaches the last character in the string, that character is now a . This time, the backreference matches. Since the engine is not inside any recursion any more, it proceeds with the remainder of the regex after the group. \b matches at the end of the string. The end of the regex is reached and radaa is returned as the overall match. If you query the groups "word" and "letter" after the match you'll get radaa and a . Those are the most recent matches of these groups that weren't backtracked.
Basically, in Ruby this regex matches any word that is an odd number of letters long and in which all the characters to the right of the middle letter are identical to the character just to the left of the middle letter. That's because Ruby only restores capturing groups when they backtrack, but not when it exits from recursion.
The solution, specific to Ruby, is to use a backreference that specifies a recursion level instead of the normal backreference used in the regex on this page.
Earlier topics in this tutorial explain regular expression recursion and regular expression subroutines . In this topic the word "recursion" refers to recursion of the whole regex, recursion of capturing groups, and subroutine calls to capturing groups. The previous topic also explained that these features handle capturing groups differently in Ruby than they do in Perl and PCRE.
Perl, PCRE, and Boost restore capturing groups when they exit from recursion. This means that backreferences in Perl, PCRE, and Boost match the same text that was matched by the capturing group at the same recursion level. This makes it possible to do things like matching palindromes .
Ruby does not restore capturing groups when it exits from recursion. Normal backreferences match the text that is the same as the most recent match of the capturing group that was not backtracked, regardless of whether the capturing group found its match at the same or a different recursion level as the backreference. Basically, normal backreferences in Ruby don't pay any attention to recursion.
But while the normal capturing group storage in Ruby does not get any special treatment for recursion, Ruby actually stores a full stack of matches for each capturing groups at all recursion levels. This stack even includes recursion levels that the regex engine has already exited from.
Backreferences in Ruby can match the same text as was matched by a capturing group at any recursion level relative to the recursion level that the backreference is evaluated at. You can do this with the same syntax for named backreferences by adding a sign and a number after the name. In most situations you will use +0 to specify that you want the backreference to reuse the text from the capturing group at the same recursion level. You can specify a positive number to reference the capturing group at a deeper level of recursion. This would be a recursion the regex engine has already exited from. You can specify a negative number to reference the capturing group a level that is less deep. This would be a recursion that is still in progress.
JGsoft V2 also supports backreferences that specify a recursion level using the same syntax as Ruby. To get the same behavior with JGsoft V2 as with Ruby, you have to use Ruby's \g syntax for your subroutine calls.
In Ruby you can use \b (?'word' (?'letter' [ a - z ] ) \g'word' \k'letter+0' | [ a - z ] ) \b to match palindrome words such as a , dad , radar , racecar , and redivider . To keep this example simple, this regex only matches palindrome words that are an odd number of letters long.
Let's see how this regex matches radar . The word boundary \b matches at the start of the string. The regex engine enters the capturing group "word". [ a - z ] matches r which is then stored in the stack for the capturing group "letter" at recursion level zero. Now the regex engine enters the first recursion of the group "word". (?'letter' [ a - z ] ) matches and captures a at recursion level one. The regex enters the second recursion of the group "word". (?'letter' [ a - z ] ) captures d at recursion level two. During the next two recursions, the group captures a and r at levels three and four. The fifth recursion fails because there are no characters left in the string for [ a - z ] to match. The regex engine must backtrack.
The regex engine must now try the second alternative inside the group "word". The second [ a - z ] in the regex matches the final r in the string. The engine now exits from a successful recursion, going one level back up to the third recursion.
After matching \g'word' the engine reaches \k'letter+0' . The backreference fails because the regex engine has already reached the end of the subject string. So it backtracks once more. The second alternative now matches the a . The regex engine exits from the third recursion.
The regex engine has again matched \g'word' and needs to attempt the backreference again. The backreference specifies +0 or the present level of recursion, which is 2. At this level, the capturing group matched d . The backreference fails because the next character in the string is r . Backtracking again, the second alternative matches d .
Now, \k'letter+0' matches the second a in the string. That's because the regex engine has arrived back at the first recursion during which the capturing group matched the first a . The regex engine exits the first recursion.
The regex engine is now back outside all recursion. That this level, the capturing group stored r . The backreference can now match the final r in the string. Since the engine is not inside any recursion any more, it proceeds with the remainder of the regex after the group. \b matches at the end of the string. The end of the regex is reached and radar is returned as the overall match.
Backreferences to other recursion levels can be easily understood if we modify our palindrome example. abcdefedcba is also a palindrome matched by the previous regular expression. Consider the regular expression \b (?'word' (?'letter' [ a - z ] ) \g'word' (?: \k'letter-1' | z ) | [ a - z ] ) \b . The backreference now wants a match the text one level less deep on the capturing group's stack. It is alternated with the letter z so that something can be matched when the backreference fails to match.
The new regex matches things like abcdefdcbaz . After a whole bunch of matching and backtracking, the second [ a - z ] matches f . The regex engine exits form a successful fifth recursion. The capturing group "letter" has stored the matches a , b , c , d , and e at recursion levels zero to four. Other matches by that group were backtracked and thus not retained.
Now the engine evaluates the backreference \k'letter-1' . The present level is 4 and the backreference specifies -1. Thus the engine attempts to match d , which succeeds. The engine exits from the fourth recursion.
The backreference continues to match c , b , and a until the regex engine has exited the first recursion. Now, outside all recursion, the regex engine again reaches \k'letter-1' . The present level is 0 and the backreference specifies -1. Since recursion level -1 never happened, the backreference fails to match. This is not an error but simply a backreference to a non-participating capturing group . But the backreference has an alternative. z matches z and \b matches at the end of the string. abcdefdcbaz was matched successfully.
You can take this as far as you like. The regular expression \b (?'word' (?'letter' [ a - z ] ) \g'word' (?: \k'letter-2' | z ) | [ a - z ] ) \b matches abcdefcbazz . \b (?'word' (?'letter' [ a - z ] ) \g'word' (?: \k'letter-99' | z ) | [ a - z ] ) \b matches abcdefzzzzzz .
Going in the opposite direction, \b (?'word' (?'letter' [ a - z ] ) \g'word' (?: \k'letter+1' | z ) | [ a - z ] ) \b matches abcdefzedcb . Again, after a whole bunch of matching and backtracking, the second [ a - z ] matches f , the regex engine is back at recursion level 4, and the group "letter" has a , b , c , d , and e at recursion levels zero to four on its stack.
Now the engine evaluates the backreference \k'letter+1' . The present level is 4 and the backreference specifies +1. The capturing group was backtracked at recursion level 5. This means we have a backreference to a non-participating group, which fails to match. The alternative z does match. The engine exits from the fourth recursion.
At recursion level 3, the backreference points to recursion level 4. Since the capturing group successfully matched at recursion level 4, it still has that match on its stack, even though the regex engine has already exited from that recursion. Thus \k'letter+1' matches e . Recursion level 3 is exited successfully.
The backreference continues to match d and c until the regex engine has exited the first recursion. Now, outside all recursion, the regex engine again reaches \k'letter+1' . The present level is 0 and the backreference specifies +1. The capturing group still retains all its previous successful recursion levels. So the backreference can still match the b that the group captured during the first recursion. Now \b matches at the end of the string. abcdefzdcb was matched successfully.
You can take this as far as you like in this direction too. The regular expression \b (?'word' (?'letter' [ a - z ] ) \g'word' (?: \k'letter+2' | z ) | [ a - z ] ) \b matches abcdefzzedc . \b (?'word' (?'letter' [ a - z ] ) \g'word' (?: \k'letter+99' | z ) | [ a - z ] ) \b matches abcdefzzzzzz .
Earlier topics in this tutorial explain regular expression recursion and regular expression subroutines . In this topic the word "recursion" refers to recursion of the whole regex, recursion of capturing groups, and subroutine calls to capturing groups.
Perl and Ruby backtrack into recursion if the remainder of the regex after the recursion fails. They try all permutations of the recursion as needed to allow the remainder of the regex to match. PCRE treats recursion as atomic . PCRE backtracks normally during the recursion, but once the recursion has matched, it does not try any further permutations of the recursion, even when the remainder of the regex fails to match. The result is that Perl and Ruby may find regex matches that PCRE cannot find, or that Perl and Ruby may find different regex matches.
Consider the regular expression aa $ | a (?R) a | a in Perl or the equivalent aa $ | a \g'0' a | a in Ruby 2.0. PCRE supports either syntax. Let's see how Perl, Ruby, and PCRE go through the matching process of this regex when aaa is the subject string.
The first alternative aa $ fails because the anchor cannot be matched between the second and third a in the string. Attempting the second alternative at the start of the string, a matches a . Now the regex engine enters the first recursion.
Inside the recursion, the first alternative matches the second and third a in the string. The regex engine exists a successful recursion. But now, the a that follows (?R) or \g'0' in the regex fails to match because the regex engine has already reached the end of the string. Thus the regex engine must backtrack. Here is where PCRE behaves differently than Perl or Ruby.
Perl and Ruby remember that inside the recursion the regex matched the second alternative and that there are three possible alternatives. Perl and Ruby backtrack into the recursion. The second alternative inside the recursion is backtracked, reducing the match so far to the first a in the string. Now the third alternative is attempted. a matches the second a in the string. The regex engine again exits successfully from the same recursion. This time, the a that follows (?R) or \g'0' in the regex matches the third a in the string. aaa is found as the overall match.
PCRE, on the other hand, remembers nothing about the recursion other than that it matched aa at the end of the string. PCRE does backtrack over the recursion, reducing the match so far to the first a in the string. But this leaves the second alternative in the regex without any further permutations to try. Thus the a at the start of the second alternative is also backtracked, reducing the match so far to nothing. PCRE continues the match attempt at the start of the string with the third alternative and finds that a matches a at the start of the string. In PCRE, this is the overall match.
You can make recursion in Perl and Ruby atomic by adding an atomic group. aa $ | a (?> (?R) ) a | a in Perl and aa $ | a (?> \g'0' ) a | a in Ruby is the same as the original regexes in PCRE.
JGsoft V2 lets you choose whether recursion should be atomic or not. Atomic recursion gives better performance, but may exclude certain matches or find different matches as illustrated above. aa $ | a (?P>0) a | a is atomic in JGsoft V2. You can remember this because this syntax for recursion uses an angle bracket just like an atomic group. You can use a number or a name instead of zero for an atomic subroutine call to a numbered or named capturing group. Any other syntax for recursion is not atomic in JGsoft V2.
Boost is of two minds. Recursion of the whole regex is atomic in Boost, like in PCRE. But Boost will backtrack into subroutine calls, like Perl. So you can do non-atomic recursion in Boost by wrapping the whole regex into a capturing group and then calling that.
The topic about recursion and capturing groups explains a regular expression to match palindromes that are an odd number of characters long. The solution seems trivial. \b (?'word' (?'letter' [ a - z ] ) (?&word) \k'letter' | [ a - z ] ? ) \b does the trick in Perl. The quantifier ? makes the [ a - z ] that matches the letter in the middle of the palindrome optional. In Ruby we can use \b (?'word' (?'letter' [ a - z ] ) \g'word' \k'letter+0' | [ a - z ] ? ) \b which adds the same quantifier to the solution that specifies the recursion level for the backreference . In PCRE, the Perl solution still matches odd-length palindromes, but not even-length palindromes.
Let's see how these regexes match or fail to match deed . PCRE starts off the same as Perl and Ruby, just as in the original regex. The group "letter" matches d . During three consecutive recursions, the group captures e , e , and d . The fourth recursion fails, because there are no characters left the match. Back in the third recursion, the first alternative is backtracked and the second alternative matches d at the end of the string. The engine exists the third recursion with a successful match. Back in the second recursion, the backreference fails because there are no characters left in the string.
Here the behavior diverges. Perl and Ruby backtrack into the third recursion and backtrack the quantifier ? that makes the second alternative optional. In the third recursion, the second alternative gives up the d that it matched at the end of the string. The engine exists the third recursion again, this time with a successful zero-length match. Back in the second recursion, the backreference still fails because the group stored e for the second recursion but the next character in the string is d . This the first alternative is backtracked and the second alternative matches the second e in the string. The second recursion is exited with success.
In the first recursion, the backreference again fails. The group stored e for the first recursion but the next character in the string is d . Again, Perl and Ruby backtrack into the second recursion to try the permutation where the second alternative finds a zero-length match. Back in the first recursion again, the backreference now matches the second e in the string. The engine leaves the first recursion with success. Back in the overall match attempt, the backreference matches the final d in the string. The word boundary succeeds and an overall match is found.
PCRE, however, does not backtrack into the third recursion. It does backtrack over the third recursion when it backtracks the first alternative in the second recursion. Now, the second alternative in the second alternative matches the second e in the string. The second recursion is exited with success.
In the first recursion, the backreference again fails. The group stored e for the first recursion but the next character in the string is d . Again, PCRE does not backtrack into the second recursion, but immediately fails the first alternative in the first recursion. The second alternative in the first recursion now matches the first e in the string. PCRE exits the first recursion with success. Back in the overall match attempt, the backreference fails, because the group captured d prior to the recursion, and the next character is the second e in the string. Backtracking again, the second alternative in the overall regex match now matches the first d in the string. Then the word boundary fails. PCRE did not find any matches.
To match palindromes of any length in PCRE, we need a regex that matches words of an even number of characters and of and number of characters separately. Free-spacing mode makes this regex easier to read:
\b
(?'word'
(?'oddword'
(?'oddletter'
[
a
-
z
]
)
(?P>oddword)
\k'oddletter'
|
[
a
-
z
]
)
|
(?'evenword'
(?'evenletter'
[
a
-
z
]
)
(?P>evenword)
?
\k'evenletter'
)
)
\b
Basically, this is two copies of the original regex combined with alternation. The first alternatives has the groups "word" and "letter" renamed to "oddword" and "oddletter". The second alternative has the groups "word" and "letter" renamed to "evenword" and "evenletter". The call (?P>evenword) is now made optional with a question mark instead of the alternative | [ a - z ] . A new group "word" combines the two groups "oddword" and "evenword" so that the word boundaries still apply to the whole regex.
The first alternative "oddword" in this regex matches a palindrome of odd length like radar in exactly the same way as the regex discussed in the topic about recursion and capturing groups does. The second alternative in the new regex is never attempted.
When the string is a palindrome of even length like deed , the new regex first tries all permutations of the first alternative. The second alternative "evenword" is attempted only after the first alternative fails to find a match.
The second alternative off in the same as the original regex. The group "evenletter" matches d . During three consecutive recursions, the group captures e , e , and d . The fourth recursion fails, because there are no characters left the match. Back in the third recursion, the regex engine notes that recursive call (?P>evenword) ? is optional. It proceeds to the backreference \k'evenletter' . The backreference fails because there are no characters left in the string. Since the recursion has no further alternatives to try, is is backtracked. The group "evenletter" must give up its most recent match and PCRE exits from the failed third recursion.
In the second recursion, the backreference fails because the capturing group matched e during that recursion but the next character in the string is d . The group gives up another match and PCRE exits from the failed second recursion.
Back in the first recursion, the backreference succeeds. The group matched the first e in the string during that recursion and the backreference matches the second. PCRE exits from the successful first recursion.
Back in the overall match attempt, the backreference succeeds again. The group matched the d at the start of the string during the overall match attempt, and the backreference matches the final d . Exiting the groups "evenword" and "word", the word boundary matches at the end of the string. deed is the overall match.
POSIX bracket expressions are a special kind of character classes . POSIX bracket expressions match one character out of a set of characters, just like regular character classes. They use the same syntax with square brackets. A hyphen creates a range, and a caret at the start negates the bracket expression.
One key syntactic difference is that the backslash is NOT a metacharacter in a POSIX bracket expression. So in POSIX, the regular expression [ \d ] matches a \ or a d . To match a ] , put it as the first character after the opening [ or the negating ^ . To match a - , put it right before the closing ] . To match a ^ , put it before the final literal - or the closing ] . Put together, [ ]\d^ - ] matches ] , \ , d , ^ or - .
The main purpose of bracket expressions is that they adapt to the user's or application's locale. A locale is a collection of rules and settings that describe language and cultural conventions, like sort order, date format, etc. The POSIX standard defines these locales.
Generally, only POSIX-compliant regular expression engines have proper and full support for POSIX bracket expressions. Some non-POSIX regex engines support POSIX character classes, but usually don't support collating sequences and character equivalents. Regular expression engines that support Unicode use Unicode properties and scripts to provide functionality similar to POSIX bracket expressions. In Unicode regex engines, shorthand character classes like \w normally match all relevant Unicode characters, alleviating the need to use locales.
Don't confuse the POSIX term "character class" with what is normally called a regular expression character class . [ x - z 0 - 9 ] is an example of what this tutorial calls a "character class" and what POSIX calls a "bracket expression". [:digit:] is a POSIX character class, used inside a bracket expression like [ x - z [:digit:] ] . The POSIX character class names must be written all lowercase.
When used on ASCII strings, these two regular expressions find exactly the same matches: a single character that is either x , y , z , or a digit. When used on strings with non-ASCII characters, the [:digit:] class may include digits in other scripts, depending on the locale.
The POSIX standard defines 12 character classes. The table below lists all 12, plus the [:ascii:] and [:word:] classes that some regex flavors also support. The table also shows equivalent character classes that you can use in ASCII and Unicode regular expressions if the POSIX classes are unavailable. The ASCII equivalents correspond exactly what is defined in the POSIX standard. The Unicode equivalents correspond to what most Unicode regex engines match. The POSIX standard does not define a Unicode locale. Some classes also have Perl-style shorthand equivalents.
Java does not support POSIX bracket expressions, but does support POSIX character classes using the \p operator. Though the \p syntax is borrowed from the syntax for Unicode properties , the POSIX classes in Java only match ASCII characters as indicated below. The class names are case sensitive. Unlike the POSIX syntax which can only be used inside a bracket expression, Java's \p can be used inside and outside bracket expressions.
The JGsoft flavor supports both the POSIX and Java syntax. Originally it matched Unicode characters using either syntax. As of JGsoft V2, it matches only ASCII characters when using the POSIX syntax, and Unicode characters when using the Java syntax.
| POSIX | Description | ASCII | Unicode | Shorthand | Java |
|---|---|---|---|---|---|
| [:alnum:] | Alphanumeric characters | [ a - z A - Z 0 - 9 ] |
[
\p{L}
\p{Nl}
\p{Nd} ] |
\p{Alnum} | |
| [:alpha:] | Alphabetic characters | [ a - z A - Z ] | \p{L} \p{Nl} | \p{Alpha} | |
| [:ascii:] | ASCII characters | [ \x00 - \x7F ] | \p{InBasicLatin} | \p{ASCII} | |
| [:blank:] | Space and tab | [ \t ] | [ \p{Zs} \t ] | \h | \p{Blank} |
| [:cntrl:] | Control characters | [ \x00 - \x1F \x7F ] | \p{Cc} | \p{Cntrl} | |
| [:digit:] | Digits | [ 0 - 9 ] | \p{Nd} | \d | \p{Digit} |
| [:graph:] | Visible characters (anything except spaces and control characters) | [ \x21 - \x7E ] | [ ^ \p{Z} \p{C} ] | \p{Graph} | |
| [:lower:] | Lowercase letters | [ a - z ] | \p{Ll} | \l | \p{Lower} |
| [:print:] | Visible characters and spaces (anything except control characters) | [ \x20 - \x7E ] | \P{C} | \p{Print} | |
| [:punct:] | Punctuation and symbols. |
[
!"
\#
$%&'()*+,
\- ./:;<=>?@ \[ \\ \] ^_`{|}~ ] |
\p{P} | \p{Punct} | |
| [:space:] | All whitespace characters, including line breaks | [ \t \r \n \v \f ] | [ \p{Z} \t \r \n \v \f ] | \s | \p{Space} |
| [:upper:] | Uppercase letters | [ A - Z ] | \p{Lu} | \u | \p{Upper} |
| [:word:] | Word characters (letters, numbers and underscores) | [ A - Z a - z 0 - 9 _ ] |
[
\p{L}
\p{Nl}
\p{Nd} \p{Pc} ] |
\w | |
| [:xdigit:] | Hexadecimal digits | [ A - F a - f 0 - 9 ] | [ A - F a - f 0 - 9 ] | \p{XDigit} |
A POSIX locale can have collating sequences to describe how certain characters or groups of characters should be ordered. In Czech, for example, ch as in chemie ("chemistry" in Czech) is a digraph . This means it should be treated as if it were one character. It is ordered between h and i in the Czech alphabet. You can use the collating sequence element [.ch.] inside a bracket expression to match ch when the Czech locale (cs-CZ) is active. The regex [ [.ch.] ] emie matches chemie . Notice the double square brackets. One pair for the bracket expression, and one pair for the collating sequence.
Other than POSIX-compliant engines part of a POSIX-compliant system, none of the regex flavors discussed in this tutorial support collating sequences.
Note that a fully POSIX-compliant regex engine treats ch as a single character when the locale is set to Czech. This means that [ ^ x ] emie also matches chemie . [ ^ x ] matches a single character that is not an x , which includes ch in the Czech POSIX locale.
In any other regular expression engine, or in a POSIX engine using a locale that does not treat ch as a digraph, [ ^ x ] emie matches the misspelled word cemie but not chemie , as [ ^ x ] cannot match the two characters ch .
Finally, note that not all regex engines claiming to implement POSIX regular expressions actually have full support for collating sequences. Sometimes, these engines use the regular expression syntax defined by POSIX, but don't have full locale support. You may want to try the above matches to see if the engine you're using does. Tcl's regexp command , for example, supports the syntax for collating sequences. But Tcl only supports the Unicode locale, which does not define any collating sequences. The result is that in Tcl, a collating sequence specifying a single character matches just that character. All other collating sequences result in an error.
A POSIX locale can define character equivalents that indicate that certain characters should be considered as identical for sorting. In French, for example, accents are ignored when ordering words. élève comes before être which comes before événement . é and ê are all the same as e , but l comes before t which comes before v . With the locale set to French, a POSIX-compliant regular expression engine matches e , é , è and ê when you use the collating sequence [=e=] in the bracket expression [ [=e=] ] .
If a character does not have any equivalents, the character equivalence token simply reverts to the character itself. [ [=x=] [=z=] ] , for example, is the same as [ xz ] in the French locale.
Like collating sequences, POSIX character equivalents are not available in any regex engine discussed in this tutorial, other than those following the POSIX standard. And those that do may not have the necessary POSIX locale support. Here too Tcl's regexp command supports the syntax for character equivalents. But the Unicode locale, the only one Tcl supports, does not define any character equivalents. This effectively means that [ [=e=] ] and [ e ] are exactly the same in Tcl, and only match e , for any character you may try instead of "e".
We saw that anchors , word boundaries , and lookaround match at a position, rather than matching a character. This means that when a regex only consists of one or more anchors, word boundaries, or lookaorunds, then it can result in a zero-length match. Depending on the situation, this can be very useful or undesirable.
In email, for example, it is common to prepend a "greater than" symbol and a space to each line of the quoted message. In VB.NET , we can easily do this with Dim Quoted As String = Regex.Replace(Original, "^", "> ", RegexOptions.Multiline) . We are using multi-line mode, so the regex ^ matches at the start of the quoted message, and after each newline. The Regex.Replace method removes the regex match from the string, and inserts the replacement string (greater than symbol and a space). Since the match does not include any characters, nothing is deleted. However, the match does include a starting position. The replacement string is inserted there, just like we want it.
Using ^ \d * $ to test if the user entered a number would give undesirable results. It causes the script to accept an empty string as a valid input. Let's see why.
There is only one "character" position in an empty string: the void after the string. The first token in the regex is ^ . It matches the position before the void after the string, because it is preceded by the void before the string. The next token is \d * . One of the star 's effects is that it makes the \d , in this case, optional. The engine tries to match \d with the void after the string. That fails. But the star turns the failure of the \d into a zero-length success. The engine proceeds with the next regex token, without advancing the position in the string. So the engine arrives at $ , and the void after the string. These match. At this point, the entire regex has matched the empty string, and the engine reports success.
The solution is to use the regex ^ \d + $ with the proper quantifier to require at least one digit to be entered. If you always make sure that your regexes cannot find zero-length matches, other than special cases such as matching the start or end of each line, then you can save yourself the headache you'll get from reading the remainder of this topic.
Not all flavors support zero-length matches. The TRegEx class in Delphi XE5 and prior always skips zero-length matches. The TPerlRegEx class does too by default in XE5 and prior, but allows you to change this via the State property. In Delphi XE6 and later, TRegEx never skips zero-length matches while TPerlRegEx does not skip them by default but still allows you to skip them via the State property. PCRE finds zero-length matches by default, but can skip them if you set PCRE_NOTEMPTY.
If a regex can find zero-length matches at any position in the string, then it will. The regex \d * matches zero or more digits. If the subject string does not contain any digits, then this regex finds a zero-length match at every position in the string. It finds 4 matches in the string abc , one before each of the three letters, and one at the end of the string.
Things get tricky when a regex can find zero-length matches at any position as well as certain non-zero-length matches. Say we have the regex \d * | x , the subject string x1 , and a regex engine allows zero-length matches. Which and how many matches do we get when iterating over all matches? The answer depends on how the regex engine advances after zero-length matches. The answer is tricky either way.
The first match attempt begins at the start of the string. \d fails to match x . But the * makes \d optional. The first alternative finds a zero-length match at the start of the string. Until here, all regex engines that allow zero-length matches do the same.
Now the regex engine is in a tricky situation. We're asking it to go through the entire string to find all non-overlapping regex matches. The first match ended at the start of the string, where the first match attempt began. The regex engine needs a way to avoid getting stuck in an infinite loop that forever finds the same zero-length match at the start of the string.
The simplest solution, which is used by most regex engines, is to start the next match attempt one character after the end of the previous match, if the previous match was zero-length. In this case, the second match attempt begins at the position between the x and the 1 in the string. \d matches 1 . The end of the string is reached. The quantifier * is satisfied with a single repetition. 1 is returned as the overall match.
The other solution, which is used by Perl , PCRE is to always start the next match attempt at the end of the previous match, regardless of whether it was zero-length or not. If it was zero-length, the engine makes note of that, as it must not allow a zero-length match at the same position. Thus Perl and PCRE begin the second match attempt also at the start of the string. The first alternative again finds a zero-length match. But this is not a valid match, so the engine backtracks through the regular expression. \d * is forced to give up its zero-length match. Now the second alternative in the regex is attempted. x matches x and the second match is found. The third match attempt begins at the position after the x in the string. The first alternative matches 1 and the third match is found.
But the regex engine isn't done yet. After x is matched, it makes one more match attempt starting at the end of the string. Here too \d * finds a zero-length match. So depending on how the engine advances after zero-length matches, it finds either three or four matches.
One exception is the JGsoft engine . The JGsoft engine advances one character after a zero-length match, like most engines do. But it has an extra rule to skip zero-length matches at the position where the previous match ended, so you can never have a zero-length match immediately adjacent to a non-zero-length match. In our example the JGsoft engine only finds two matches: the zero-length match at the start of the string, and 1 .
Python advances after zero-length matches. The gsub() function to search-and-replace skips zero-length matches at the position where the previous non-zero-length match ended, but the finditer() function returns those matches. So a search-and-replace in Python gives the same results as the Just Great Software applications, but listing all matches adds the zero-length match at the end of the string.
The regexp functions in R and PHP are based on PCRE, so they avoid getting stuck on a zero-length match by backtracking like PCRE does. But the gsub() function to search-and-replace in R also skips zero-length matches at the position where the previous non-zero-length match ended, like Python does. The other regexp functions in R and all the functions in PHP do allow zero-length matches immediately adjacent to non-zero-length matches, just like PCRE itself.
A regular expression such as $ all by itself can find a zero-length match at the end of the string. If you would query the engine for the character position, it would return the length of the string if string indexes are zero-based, or the length+1 if string indexes are one-based in your programming language. If you would query the engine for the length of the match, it would return zero.
What you have to watch out for is that String[Regex.MatchPosition] may cause an access violation or segmentation fault, because MatchPosition can point to the void after the string. This can also happen with ^ and ^ $ in multi-line mode if the last character in the string is a newline.
The anchor \G matches at the position where the previous match ended. During the first match attempt, \G matches at the start of the string in the way \A does.
Applying \G \w to the string test string matches t . Applying it again matches e . The 3rd attempt yields s and the 4th attempt matches the second t in the string. The fifth attempt fails. During the fifth attempt, the only place in the string where \G matches is after the second t . But that position is not followed by a word character, so the match fails.
With some regex flavors or tools, \G matches at the start of the match attempt, rather than at the end of the previous match. This is the case with Ruby and the Just Great Software applications . In EditPad Pro \G matches at the position of the text cursor. When a match is found, EditPad Pro will select the match, and move the text cursor to the end of the match. The result is that \G matches at the end of the previous match result only when you do not move the text cursor between two searches. All in all, this makes a lot of sense in the context of a text editor.
The distinction between the end of the previous match and the start of the match attempt is also important if your regular expression can find zero-length matches . Most regex engines advance through the string after a zero-length match . In that case, the start of the match attempt is one character further in the string than the end of the previous match attempt. .NET , Java , and Boost advance this way and also match \G at the end of the previous match attempt. Thus \G fails to match when .NET, Java, and Boost have advanced after a zero-length match.
In Perl , the position where the last match ended is a "magical" value that is remembered separately for each string variable. The position is not associated with any regular expression. This means that you can use \G to make a regex continue in a subject string where another regex left off.
If a match attempt fails, the stored position for \G is reset to the start of the string. To avoid this, specify the continuation modifier /c .
All this is very useful to make several regular expressions work together. E.g. you could parse an HTML file in the following fashion:
while
($string =~ m/</g) {
if
($string =~ m/\GB>/c) {
# Bold
}
elsif
($string =~ m/\GI>/c) {
# Italics
}
else
{
# ...etc...
}
}
The regex in the while loop searches for the tag's opening bracket, and the regexes inside the loop check which tag we found. This way you can parse the tags in the file in the order they appear in the file, without having to write a single big regex that matches all tags you are interested in.
This flexibility is not available with most other programming languages. E.g. in Java , the position for \G is remembered by the Matcher object. The Matcher is strictly associated with a single regular expression and a single subject string. What you can do though is to add a line of code to make the match attempt of the second Matcher start where the match of the first Matcher ended. Then \G will match at this position.
Normally, \A is a start-of-string anchor . But in Tcl, the anchor \A matches at the start of the match attempt rather than at the start of the string. With the GNU flavors , \` does the same. This makes no difference if you're only making one call to regexp in Tcl or regexec() in the GNU library. It can make a difference if you make a second call to find another match in the remainder of the string after the first match. \A or \` then matches at the end of the first match, instead of failing to match as start-of-string anchors normally do. Strangely enough, the caret does not have this issue in either Tcl or GNU's library.
A regular expression (regex or regexp for short) is a special text string for describing a search pattern. You can think of regular expressions as wildcards on steroids. You are probably familiar with wildcard notations such as *.txt to find all text files in a file manager. The regex equivalent is ^ . * \. txt $ .
But you can do much more with regular expressions. In a text editor like EditPad Pro or a specialized text processing tool like PowerGREP , you could use the regular expression \b [ A - Z 0 - 9 ._%+ - ] + @ [ A - Z 0 - 9 . - ] + \. [ A - Z ] {2,} \b to search for an email address. Any email address, to be exact. A very similar regular expression (replace the first \b with ^ and the last one with $ ) can be used by a programmer to check whether the user entered a properly formatted email address . In just one line of code, whether that code is written in Perl , PHP , Java , a .NET language , or a multitude of other languages.
If you just want to get your feet wet with regular expressions, take a look at the one-page regular expressions quick start . While you can't learn to efficiently use regular expressions from this brief overview, it's enough to be able to throw together a bunch of simple regular expressions. Each section in the quick start links directly to detailed information in the tutorial.
Do not worry if the above example or the quick start make little sense to you. Any non-trivial regex looks daunting to anybody not familiar with them. But with just a bit of experience, you will soon be able to craft your own regular expressions like you have never done anything else. The free Regular-Expressions.info Tutorial explains everything bit by bit.
This tutorial is quite unique because it not only explains the regex syntax, but also describes in detail how the regex engine actually goes about its work. You will learn quite a lot, even if you have already been using regular expressions for some time. This will help you to understand quickly why a particular regex does not do what you initially expected, saving you lots of guesswork and head scratching when writing more complex regexes.
A replacement string, also known as the replacement text, is the text that each regular expression match is replaced with during a search-and-replace. In most applications, the replacement text supports special syntax that allows you to reuse the text matched by the regular expression or parts thereof in the replacement. This website also includes a complete replacement strings tutorial that explains this syntax. While replacement strings are fairly simple compared with regular expressions, there is still great variety between the syntax used by various applications and their actual behavior.
There are many software applications and programming languages that support regular expressions. If you are a programmer, you can save yourself lots of time and effort. You can often accomplish with a single regular expression in one or a few lines of code what would otherwise take dozens or hundreds.
Many applications and programming languages have their own implementation of regular expressions, often with slight and sometimes with significant differences from other implementations. When two applications use a different implementation of regular expressions, we say that they use different "regular expression flavors". Unlike most other regex tutorials, the tutorial on this website covers all the popular regular expression flavors, and indicates the differences that you should watch out for.
If you are not a programmer, you can use regular expressions in many situations just as well. They make finding information a lot easier. You can use them in powerful search and replace operations to quickly make changes across large numbers of files. A simple example is gr [ ae ] y which finds both spellings of the word gray in one operation, instead of two. There are many text editors and search and replace tools with decent regex support.
If you're hungry for more information on regular expressions after reading this website, there are a variety of books on the subject.
This quick start gets you up to speed quickly with regular expressions. Obviously, this brief introduction cannot explain everything there is to know about regular expressions. For detailed information, consult the regular expressions tutorial . Each topic in the quick start corresponds with a topic in the tutorial, so you can easily go back and forth between the two.
Many applications and programming languages have their own implementation of regular expressions, often with slight and sometimes with significant differences from other implementations. When two applications use a different implementation of regular expressions, we say that they use different "regular expression flavors". This quick start explains the syntax supported by the most popular regular expression flavors.
A regular expression, or regex for short, is a pattern describing a certain amount of text. On this website, regular expressions are highlighted in red as regex . This is actually a perfectly valid regex. It is the most basic pattern, simply matching the literal text regex . Matches are highlighted in blue on this site. We use the term "string" to indicate the text that the regular expression is applied to. Strings are highlighted in green .
Characters with special meanings in regular expressions are highlighted in various different colors. The regex ( [ Rr ] egex p ? ) \? shows meta tokens in purple, grouping in green, character classes in orange, quantifiers and other special tokens in blue, and escaped characters in gray.
The most basic regular expression consists of a single literal character, such as a . It matches the first occurrence of that character in the string. If the string is Jack is a boy , it matches the a after the J .
This regex can match the second a too. It only does so when you tell the regex engine to start searching through the string after the first match. In a text editor, you can do so by using its "Find Next" or "Search Forward" function. In a programming language, there is usually a separate function that you can call to continue searching through the string after the previous match.
Twelve characters have special meanings in regular expressions: the backslash \ , the caret ^ , the dollar sign $ , the period or dot . , the vertical bar or pipe symbol | , the question mark ? , the asterisk or star * , the plus sign + , the opening parenthesis ( , the closing parenthesis ) , the opening square bracket [ , and the opening curly brace { . These special characters are often called "metacharacters". Most of them are errors when used alone.
If you want to use any of these characters as a literal in a regex, you need to escape them with a backslash. If you want to match 1+1=2 , the correct regex is 1 \+ 1=2 . Otherwise, the plus sign has a special meaning.
Learn more about literal characters
A "character class" matches only one out of several characters. To match an a or an e, use [ ae ] . You could use this in gr [ ae ] y to match either gray or grey . A character class matches only a single character. gr [ ae ] y does not match graay , graey or any such thing. The order of the characters inside a character class does not matter.
You can use a hyphen inside a character class to specify a range of characters. [ 0 - 9 ] matches a single digit between 0 and 9. You can use more than one range. [ 0 - 9 a - f A - F ] matches a single hexadecimal digit, case insensitively. You can combine ranges and single characters. [ 0 - 9 a - f x A - F X ] matches a hexadecimal digit or the letter X.
Typing a caret after the opening square bracket negates the character class. The result is that the character class matches any character that is not in the character class. q [ ^ x ] matches qu in question . It does not match Iraq since there is no character after the q for the negated character class to match.
Learn more about character classes
\d matches a single character that is a digit, \w matches a "word character" (alphanumeric characters plus underscore), and \s matches a whitespace character (includes tabs and line breaks). The actual characters matched by the shorthands depends on the software you're using. In modern applications, they include non-English letters and numbers.
Learn more about shorthand character classes
You can use special character sequences to put non-printable characters in your regular expression. Use \t to match a tab character (ASCII 0x09), \r for carriage return (0x0D) and \n for line feed (0x0A). More exotic non-printables are \a (bell, 0x07), \e (escape, 0x1B), \f (form feed, 0x0C) and \v (vertical tab, 0x0B). Remember that Windows text files use \r\n to terminate lines, while UNIX text files use \n .
If your application supports Unicode , use \uFFFF or \x{FFFF} to insert a Unicode character. \u20AC or \x{20AC} matches the euro currency sign.
If your application does not support Unicode, use \xFF to match a specific character by its hexadecimal index in the character set. \xA9 matches the copyright symbol in the Latin-1 character set.
All non-printable characters can be used directly in the regular expression, or as part of a character class.
Learn more about non-printable characters
The dot matches a single character, except line break characters. Most applications have a "dot matches all" or "single line" mode that makes the dot match any single character, including line breaks.
gr . y matches gray , grey , gr%y , etc. Use the dot sparingly. Often, a character class or negated character class is faster and more precise.
Anchors do not match any characters. They match a position. ^ matches at the start of the string, and $ matches at the end of the string. Most regex engines have a "multi-line" mode that makes ^ match after any line break, and $ before any line break. E.g. ^ b matches only the first b in bob .
\b matches at a word boundary. A word boundary is a position between a character that can be matched by \w and a character that cannot be matched by \w . \b also matches at the start and/or end of the string if the first and/or last characters in the string are word characters. \B matches at every position where \b cannot match.
Alternation is the regular expression equivalent of "or". cat | dog matches cat in About cats and dogs . If the regex is applied again, it matches dog . You can add as many alternatives as you want: cat | dog | mouse | fish .
Alternation has the lowest precedence of all regex operators. cat | dog food matches cat or dog food . To create a regex that matches cat food or dog food , you need to group the alternatives: ( cat | dog ) food .
The question mark makes the preceding token in the regular expression optional. colo u ? r matches colour or color .
The asterisk or star tells the engine to attempt to match the preceding token zero or more times. The plus tells the engine to attempt to match the preceding token once or more. < [ A - Z a - z ] [ A - Z a - z 0 - 9 ] * > matches an HTML tag without any attributes. < [ A - Z a - z 0 - 9 ] + > is easier to write but matches invalid tags such as <1> .
Use curly braces to specify a specific amount of repetition. Use \b [ 1 - 9 ] [ 0 - 9 ] {3} \b to match a number between 1000 and 9999. \b [ 1 - 9 ] [ 0 - 9 ] {2,4} \b matches a number between 100 and 99999.
The repetition operators or quantifiers are greedy. They expand the match as far as they can, and only give back if they must to satisfy the remainder of the regex. The regex < . + > matches <EM>first</EM> in This is a <EM>first</EM> test .
Place a question mark after the quantifier to make it lazy. < . + ? > matches <EM> in the above string.
A better solution is to follow my advice to use the dot sparingly. Use < [ ^ <> ] + > to quickly match an HTML tag without regard to attributes. The negated character class is more specific than the dot, which helps the regex engine find matches quickly.
Learn more about greedy and lazy quantifiers
Place parentheses around multiple tokens to group them together. You can then apply a quantifier to the group. E.g. Set ( Value ) ? matches Set or SetValue .
Parentheses create a capturing group. The above example has one group. After the match, group number one contains nothing if Set was matched. It contains Value if SetValue was matched. How to access the group's contents depends on the software or programming language you're using. Group zero always contains the entire regex match.
Use the special syntax Set (?: Value ) ? to group tokens without creating a capturing group. This is more efficient if you don't plan to use the group's contents. Do not confuse the question mark in the non-capturing group syntax with the quantifier.
Learn more about grouping and capturing
Within the regular expression, you can use the backreference \1 to match the same text that was matched by the capturing group. ( [ abc ] ) = \1 matches a=a , b=b , and c=c . It does not match anything else. If your regex has multiple capturing groups, they are numbered counting their opening parentheses from left to right.
Learn more about backreferences
If your regex has many groups, keeping track of their numbers can get cumbersome. Make your regexes easier to read by naming your groups. (?<mygroup> [ abc ] ) = \k<mygroup> is identical to ( [ abc ] ) = \1 , except that you can refer to the group by its name.
\p{L} matches a single character that is in the given Unicode category. L stands for letter. \P{L} matches a single character that is not in the given Unicode category. You can find a complete list of Unicode categories in the tutorial.
Learn more about Unicode regular expressions
Lookaround is a special kind of group. The tokens inside the group are matched normally, but then the regex engine makes the group give up its match and keeps only the result. Lookaround matches a position, just like anchors. It does not expand the regex match.
q (?= u ) matches the q in question , but not in Iraq . This is positive lookahead. The u is not part of the overall regex match. The lookahead matches at each position in the string before a u .
q (?! u ) matches q in Iraq but not in question . This is negative lookahead. The tokens inside the lookahead are attempted, their match is discarded, and the result is inverted.
To look backwards, use lookbehind. (?<= a ) b matches the b in abc . This is positive lookbehind. (?<! a ) b fails to match abc .
You can use a full-fledged regular expression inside lookahead. Most applications only allow fixed-length expressions in lookbehind.
Many application have an option that may be labeled "free-spacing" or "ignore whitespace" or "comments" that makes the regular expression engine ignore unescaped spaces and line breaks and that makes the # character start a comment that runs until the end of the line. This allows you to use whitespace to format your regular expression in a way that makes it easier for humans to read and thus makes it easier to maintain.
Basically, a regular expression is a pattern describing a certain amount of text. Their name comes from the mathematical theory on which they are based. But we will not dig into that. You will usually find the name abbreviated to "regex" or "regexp". This tutorial uses "regex", because it is easy to pronounce the plural "regexes". On this website, regular expressions are highlighted in red as regex .
This first example is actually a perfectly valid regex. It is the most basic pattern, simply matching the literal text regex . A "match" is the piece of text, or sequence of bytes or characters that pattern was found to correspond to by the regex processing software. Matches are highlighted in blue on this site.
\b [ A - Z 0 - 9 ._%+ - ] + @ [ A - Z 0 - 9 . - ] + \. [ A - Z ] {2,} \b is a more complex pattern. It describes a series of letters, digits, dots, underscores, percentage signs and hyphens, followed by an at sign, followed by another series of letters, digits and hyphens, finally followed by a single dot and two or more letters. In other words: this pattern describes an email address . This also shows the syntax highlighting applied to regular expressions on this site. Word boundaries and quantifiers are blue, character classes are orange, and escaped literals are gray. You'll see additional colors like green for grouping and purple for meta tokens later in the tutorial.
With the above regular expression pattern, you can search through a text file to find email addresses, or verify if a given string looks like an email address. This tutorial uses the term "string" to indicate the text that the regular expression is applied to. This website highlights them in green . The term "string" or "character string" is used by programmers to indicate a sequence of characters. In practice, you can use regular expressions with whatever data you can access using the application or programming language you are working with.
A regular expression "engine" is a piece of software that can process regular expressions, trying to match the pattern to the given string. Usually, the engine is part of a larger application and you do not access the engine directly. Rather, the application invokes it for you when needed, making sure the right regular expression is applied to the right file or data.
As usual in the software world, different regular expression engines are not fully compatible with each other. The syntax and behavior of a particular engine is called a regular expression flavor. This tutorial covers all the popular regular expression flavors, including Perl , PCRE , PHP , .NET , Java , JavaScript , XRegExp , VBScript , Python , Ruby , Delphi , R , Tcl , POSIX , and many others . The tutorial alerts you when these flavors require different syntax or show different behavior. Even if your application is not explicitly covered by the tutorial, it likely uses a regex flavor that is covered, as most applications are developed using one of the programming environments or regex libraries just mentioned.
You can easily try the following yourself in a text editor that supports regular expressions, such as EditPad Pro . If you do not have such an editor, you can download the free evaluation version of EditPad Pro to try this out. EditPad Pro's regex engine is fully functional in the demo version.
As a quick test, copy and paste the text of this page into EditPad Pro. Then select Search|Multiline Search Panel in the menu. In the search panel that appears near the bottom, type in regex in the box labeled "Search Text". Mark the "Regular expression" checkbox, and click the Find First button. This is the leftmost button on the search panel. See how EditPad Pro's regex engine finds the first match. Click the Find Next button, which sits next to the Find First button, to find further matches. When there are no further matches, the Find Next button's icon flashes briefly.
Now try to search using the regex reg ( ular expression s ? | ex ( p | es ) ? ) . This regex finds all names, singular and plural, I have used on this page to say "regex". If we only had plain text search, we would have needed 5 searches. With regexes, we need just one search. Regexes save you time when using a tool like EditPad Pro. Select Count Matches in the Search menu to see how many times this regular expression can match the file you have open in EditPad Pro.
If you are a programmer, your software will run faster since even a simple regex engine applying the above regex once will outperform a state of the art plain text search algorithm searching through the data five times. Regular expressions also reduce development time. With a regex engine, it takes only one line (e.g. in Perl, PHP, Python, Ruby, Java, or .NET) or a couple of lines (e.g. in C using PCRE) of code to, say, check if the user's input looks like a valid email address .
Regex Tutorial Table of Contents
A replacement string, also known as the replacement text, is the text that each regular expression match is replaced with during a search-and-replace. In most applications, the replacement text supports special syntax that allows you to reuse the text matched by the regular expression or parts thereof in the replacement. This tutorial explains this syntax. While replacement strings are fairly simple compared with regular expressions, there is still great variety between the syntax used by various applications and their actual behavior.
On this website, replacement strings are shown as replace like you would enter them in the Replace box of an application. Literal text in the replacement is highlighted in yellow. As $& \$ shows, special tokens are highlighted in blue and escaped characters in gray.
Literal Characters and Special Characters
The simplest replacement text consists of only literal characters. Certain characters have special meanings in replacement strings and have to be escaped. Escaping rules may get a bit complicated when using replacement strings in software source code.
Non-printable characters such as control characters and special spacing or line break characters are easier to enter using control character escapes or hexadecimal escapes.
Reinserting the entire regex match into the replacement text allows a search-and-replace to insert text before and after regular expression matches without really replacing anything.
Backreferences to named and numbered capturing groups in the regular expression allow the replacement text to reuse parts of the text matched by the regular expression.
Some applications support special tokens in replacement strings that allow you to insert the subject string or the part of the subject string before or after the regex match. This can be useful when the replacement text syntax is used to collect search matches and their context instead of making replacements in the subject string.
Some applications can insert the text matched by the regex or by capturing groups converted to uppercase or lowercase.
Some applications can use one replacement or another replacement depending on whether a capturing group participated in the match. This allows you to use different replacements for different matches of the regular expression.
These tools and utilities have regular expressions as the core of their functionality.
grep - The utility from the UNIX world that first made regular expressions popular
PowerGREP - Next generation grep for Microsoft Windows
RegexBuddy - Learn, create, understand, test, use and save regular expressions. RegexBuddy makes working with regular expressions easier than ever before.
RegexMagic - Generate regular expressions using RegexMagic's powerful patterns instead of the cryptic regular expression syntax.
There are a lot of applications these days that support regular expressions in one way or another, enhancing certain part of their functionality. But certain applications stand out from the crowd by implementing a full-featured Perl-style regular expression flavor and allowing regular expressions to be used instead of literal search terms throughout the application.
EditPad Lite - Basic text editor that has all the essential features for text editing, including powerful regex-based search and replace.
EditPad Pro - Convenient text editor with a powerful regex-based search and replace feature, as well as regex-based customizable syntax coloring and file navigation.
If you are a programmer, you can save a lot of coding time by using regular expressions. With a regular expression, you can do powerful string parsing in only a handful lines of code, or maybe even just a single line. A regex is faster to write and easier to debug and maintain than dozens or hundreds of lines of code to achieve the same by hand.
Boost - Free C++ source libraries with comprehensive regex support that was later standardized by C++11. But there are significant differences in Boost's regex flavors and the flavors in std::regex implementations.
Delphi - Delphi XE and later ship with RegularExpressions and RegularExpressionsCore units that wrap the PCRE library. For older Delphi versions, you can use the TPerlRegEx component, which is the unit that the RegularExpressionsCore unit is based on.
Gnulib - Gnulib or the GNU Portability Library includes many modules, including a regex module. It implements both POSIX flavors, as well as these two flavors with added GNU extensions .
Groovy - Groovy uses Java's java.util.regex package for regular expressions support. Groovy adds only a few language enhancements that allow you to instantiate the Pattern and Matcher classes with far fewer keystrokes.
Java - Java 4 and later include an excellent regular expressions library in the java.util.regex package.
JavaScript - If you use JavaScript to validate user input on a web page at the client side, using JavaScript's built-in regular expression support will greatly reduce the amount of code you need to write.
.NET (dot net) - Microsoft's new development framework includes a poorly documented, but very powerful regular expression package, that you can use in any .NET-based programming language such as C# (C sharp) or VB.NET.
PCRE - Popular open source regular expression library written in ANSI C that you can link directly into your C and C++ applications, or use through an .so (UNIX/Linux) or a .dll (Windows).
Perl - The text-processing language that gave regular expressions a second life, and introduced many new features. Regular expressions are an essential part of Perl.
PHP - Popular language for creating dynamic web pages, with three sets of regex functions. Two implement POSIX ERE, while the third is based on PCRE.
POSIX - The POSIX standard defines two regular expression flavors that are implemented in many applications, programming languages and systems.
PowerShell - Windows PowerShell is a programming language from Microsoft that is primarily designed for system administration. Since PowerShell is built on top of .NET, it's built-in regex operators -match and -replace use the .NET regex flavor. PowerShell can also access the .NET Regex classes directly.
Python - Popular high-level scripting language with a comprehensive built-in regular expression library
R - The R Language is the programming languages used in the R Project for statistical computing. It has built-in support for regular expressions based on POSIX and PCRE.
Ruby - Another popular high-level scripting language with comprehensive regular expression support as a language feature.
std::regex - Regex support part of the standard C++ library defined in C++11 and previously in TR1.
Tcl - Tcl, a popular "glue" language, offers three regex flavors. Two POSIX-compatible flavors, and an "advanced" Perl-style flavor.
VBScript - Microsoft scripting language used in ASP (Active Server Pages) and Windows scripting, with a built-in RegExp object implementing the regex flavor defined in the JavaScript standard.
Visual Basic 6 - Last version of Visual Basic for Win32 development. You can use the VBScript RegExp object in your VB6 applications.
wxWidgets - Popular open source windowing toolkit. The wxRegEx class encapsulates the "Advanced Regular Expression" engine originally developed for Tcl.
XML Schema - The W3C XML Schema standard defines its own regular expression flavor for validating simple types using pattern facets.
Xojo - Cross-platform development tool formerly known as REALbasic, with a built-in RegEx class based on PCRE.
XQuery and XPath - The W3C standard for XQuery 1.0 and XPath 2.0 Functions and Operators extends the XML Schema regex flavor to make it suitable for full text search.
XRegExp - Open source JavaScript library that enhances the regex syntax and eliminates many cross-browser inconsistencies and bugs.
Modern databases often offer built-in regular expression features that can be used in SQL statements to filter columns using a regular expression. With some databases you can also use regular expressions to extract the useful part of a column, or to modify columns using a search-and-replace.
MySQL - MySQL's REGEXP operator works just like the LIKE operator, except that it uses a POSIX Extended Regular Expression.
Oracle - Oracle Database 10g adds 4 regular expression functions that can be used in SQL and PL/SQL statements to filter rows and to extract and replace regex matches. Oracle implements POSIX Extended Regular Expressions.
PostgreSQL - PostgreSQL provides matching operators and extraction and substitution functions using the "Advanced Regular Expression" engine also used by Tcl.

Below, you will find many example patterns that you can use for and adapt to your own purposes. Key techniques used in crafting each regex are explained, with links to the corresponding pages in the tutorial where these concepts and techniques are explained in great detail.
If you are new to regular expressions, you can take a look at these examples to see what is possible. Regular expressions are very powerful. They do take some time to learn. But you will earn back that time quickly when using regular expressions to automate searching or editing tasks in EditPad Pro or PowerGREP , or when writing scripts or applications in a variety of languages .
RegexBuddy offers the fastest way to get up to speed with regular expressions. RegexBuddy will analyze any regular expression and present it to you in a clearly to understand, detailed outline. The outline links to RegexBuddy's regex tutorial (the same one you find on this website), where you can always get in-depth information with a single click.
Oh, and you definitely do not need to be a programmer to take advantage of regular expressions!
<TAG \b [ ^ > ] * > ( . * ? ) </TAG> matches the opening and closing pair of a specific HTML tag. Anything between the tags is captured into the first backreference . The question mark in the regex makes the star lazy , to make sure it stops before the first closing tag rather than before the last, like a greedy star would do. This regex will not properly match tags nested inside themselves, like in <TAG>one<TAG>two</TAG>one</TAG> .
< ( [ A - Z ] [ A - Z 0 - 9 ] * ) \b [ ^ > ] * > ( . * ? ) </ \1 > will match the opening and closing pair of any HTML tag. Be sure to turn off case sensitivity. The key in this solution is the use of the backreference \1 in the regex. Anything between the tags is captured into the second backreference. This solution will also not match tags nested in themselves.
You can easily trim unnecessary whitespace from the start and the end of a string or the lines in a text file by doing a regex search-and-replace. Search for ^ [ \t ] + and replace with nothing to delete leading whitespace (spaces and tabs). Search for [ \t ] + $ to trim trailing whitespace. Do both by combining the regular expressions into ^ [ \t ] + | [ \t ] + $ . Instead of [ \t ] which matches a space or a tab, you can expand the character class into [ \t \r \n ] if you also want to strip line breaks. Or you can use the shorthand \s instead.
Numeric Ranges . Since regular expressions work with text rather than numbers, matching specific numeric ranges requires a bit of extra care.
Matching a Floating Point Number . Also illustrates the common mistake of making everything in a regular expression optional.
Matching an Email Address . There's a lot of controversy about what is a proper regex to match email addresses. It's a perfect example showing that you need to know exactly what you're trying to match (and what not), and that there's always a trade-off between regex complexity and accuracy.
Matching Valid Dates . A regular expression that matches 31-12-1999 but not 31-13-1999.
Finding or Verifying Credit Card Numbers . Validate credit card numbers entered on your order form. Find credit card numbers in documents for a security audit.
Matching Complete Lines . Shows how to match complete lines in a text file rather than just the part of the line that satisfies a certain requirement. Also shows how to match lines in which a particular regex does not match.
Removing Duplicate Lines or Items . Illustrates simple yet clever use of capturing parentheses or backreferences.
Regex Examples for Processing Source Code . How to match common programming language syntax such as comments, strings, numbers, etc.
Two Words Near Each Other . Shows how to use a regular expression to emulate the "near" operator that some tools have.
Catastrophic Backtracking . If your regular expression seems to take forever, or simply crashes your application, it has likely contracted a case of catastrophic backtracking. The solution is usually to be more specific about what you want to match, so the number of matches the engine has to try doesn't rise exponentially.
Making Everything Optional . If all the parts in your regex are optional, it will match a zero-length string anywhere. Your regex will need to express the facts that different parts are optional depending on which parts are present.
Repeating a Capturing Group vs. Capturing a Repeated Group . Repeating a capturing group will capture only the last iteration of the group. Capture a repeated group if you want to capture all iterations.
Mixing Unicode and 8-bit Character Codes . Using 8-bit character codes like \x80 with a Unicode engine and subject string may give unexpected results.

The regular expressions reference on this website functions both as a reference to all available regex syntax and as a comparison of the features supported by the regular expression flavors discussed in the tutorial . The reference tables pack an incredible amount of information. To get the most out of them, follow this legend to learn how to read them.
The tables have six columns for each regular expression feature. The first four explain the feature.
| Feature | The name of the feature, which also servers as a link to the relevant section in the tutorial. |
|---|---|
| Syntax | The actual regex syntax for this feature. If the syntax is fixed, it is simply shown as such. If the syntax has variable elements, the syntax is described. |
| Description | Summary of what the feature does. |
| Example | Functional regular expression that demonstrates the feature. |
The final two columns indicate whether your two chosen regular expression flavors support this particular feature. You can change the flavors using the drop-down lists above the table. There are many possible indicators.
| YES | All versions of this flavor support this feature. |
| 3.0 | Version 3.0 and all later versions of this flavor support this feature. Earlier versions do not support it. |
| 2.0 only | Only version 2.0 supports this feature. Earlier and later versions do not support it. |
| 2.0–2.9 | Only versions 2.0 through 2.9 supports this feature. Earlier and later versions do not support it. |
| Unicode | This feature works with Unicode characters in all versions of this flavor. |
| code page | This feature works with the characters in the active code page in all versions of this flavor. |
| ASCII | This feature works with ASCII characters only in all versions of this flavor. |
| 3.0 Unicode | This feature works with Unicode characters in versions 3.0 and later of this flavor. Earlier versions do not support it at all. |
|
3.0 Unicode
2.0 ASCII |
This feature works with Unicode characters in versions 3.0 and later this flavor. It works with ASCII characters in versions 2.0 through 2.9. Earlier versions do not support it at all. |
|
3.0 Unicode
2.0 code page |
This feature works with Unicode characters in versions 3.0 and later this flavor. It works with the characters in the active code page in versions 2.0 through 2.9. Earlier versions do not support it at all. |
| string | The regex flavor does not support this syntax. But string literals in the programming language that this regex flavor is normally used with do support this syntax. |
|
3.0
1.0 string |
Version 3.0 and later of this regex flavor support this syntax. Earlier versions of the regex flavor do not support this syntax. But string literals in the programming language that this regex flavor is normally used with have supported this syntax since version 1.0. |
| option | All versions of this regex flavor support this feature if you set a particular option or precede it with a particular mode modifier . |
|
option
3.0 |
Version 3.0 and all later versions of this regex flavor support this feature if you set a particular option or precede it with a particular mode modifier . Earlier versions either do not support the syntax at all or do not support the mode modifier to change the behavior of the syntax to what the feature describes. |
|
3.0
2.0 fail |
Version 3.0 and all later versions of this regex flavor support this feature. Version 2.0 all later releases prior to 3.0 recognize the syntax, but always fail to match this regex token. Versions prior to 2.0 do not support the syntax. |
| no | No version of this flavor support this feature. No indication is given as to what this syntax actually does. The same syntax may be used for a different feature which is indicated elsewhere in the reference table. Or the syntax may trigger an error or it may be interpreted as plain text. |
| n/a | This feature is not applicable to this regex flavor. Features that describe the behavior of certain syntax introduced earlier in the reference table show n/a for flavors that do not support that syntax at all. |
| fail | The syntax is recognized by the flavor and regular expressions using it work, but this particular regex token always fails to match. The regex can only find matches if this token is made optional by alternation or a quantifier. |
| 2.0–2.9 fail | Versions 2.0 through 2.9 recognize the syntax, but always fail to match this regex token. Earlier and later versions either don't recognize the syntax or treat it as a syntax error. |
| ignored | The syntax is recognized by the flavor but it does not do anything useful. This particular regex token always finds a zero-length match. |
| error | The syntax is recognized by the flavor but it is treated as a syntax error. |
When this legend says "all versions" or "no version", that means all or none of the versions of each flavor that are covered by the reference tables:
| JGsoft |
V1: EditPad Pro 6 and 7; PowerGREP 3 and 4; AceText 3
V2: PowerGREP 5 |
|---|---|
| .NET | 1.0–4.7.1 |
| Java | 4–8 |
| Perl | 5.8–5.26 |
| PCRE | 4.0–8.41 |
| PCRE2 | 10.00–10.23 |
| PHP | 5.0.0–7.1.14 |
| Delphi | XE–XE8 & 10–10.2; TRegEx only; also applies to C++Builder XE–XE8 & 10–10.2 |
| R | 2.14.0–3.4.3 |
| JavaScript | Latest versions of Chrome, Edge, and Firefox |
| VBScript | VBscript and Internet Explorer in quirks mode |
| XRegExp | 2.0.0–3.0.0 |
| Python | 2.4–3.6 |
| Ruby | 1.8–2.5 |
| std::regex | Visual C++ 2008–2017 (Dinkumware std library) |
| boost::regex | 1.38–1.39 & 1.42–1.65 |
| Tcl ARE | 8.4–8.6 |
| POSIX BRE | IEEE Std 1003.1 |
| POSIX ERE | IEEE Std 1003.1 |
| GNU BRE | |
| GNU ERE | |
| Oracle | 10gR1, 10gR2, 11gR1, 11gR2, 12c |
| XML | 1.0–1.1 |
| XPath | 2.0–3.1 |
For the .NET flavor, some features are indicated with "ECMA" or "non-ECMA". That means the feature is only supported when RegexOptions.ECMAScript is set or is not set. Features indicated with "non-ECMA Unicode" match ASCII characters when RegexOptions.ECMAScript is set and Unicode characters when RegexOptions.ECMAScript is not set. Everything that applies to .NET 2.0 or later also applies to any version of .NET Core. The Visual Studio IDE uses the non-ECMA .NET flavor starting with VS 2012.
For the std::regex and boost::regex flavor there are additional indicators ECMA, basic, extended, grep, egrep, and awk. When one or more of these appear, that means that the feature is only supported if you specify one of these grammars when compiling your regular expression. Features with Unicode indicators match Unicode characters when using std::wregex or boost::wregex on wide character strings. In the replacement string reference, the additional indicators are sed and default. When either one appears, the feature is only supported when you either pass or don't pass match_flag_type::format_sed to regex_replace(). For boost, there is one more replacement indicator "all" that indicates the feature is only supported when you pass match_flag_type::format_all to regex_replace().
For the PCRE2 flavor, some replacement string features are indicated with "extended". This means the feature is only supported when you pass PCRE2_SUBSTITUTE_EXTENDED to pcre2_substitute .

The introduction explains how to read the replacement strings reference tables.
Literal Characters, Special Characters, and Non-Printable Characters
The simplest replacement text consists of only literal characters. Certain characters have special meanings in replacement strings and have to be escaped. Escaping rules may get a bit complicated when using replacement strings in software source code. Non-printable characters such as control characters and special spacing or line break characters are easier to enter using control character escapes or hexadecimal escapes.
Matched Text and Backreferences
Reinserting the entire regex match into the replacement text allows a search-and-replace to insert text before and after regular expression matches without really replacing anything. Backreferences to named and numbered capturing groups in the regular expression allow the replacement text to reuse parts of the text matched by the regular expression.
Match Context and Case Conversion
Some applications support special tokens in replacement strings that allow you to insert the subject string or the part of the subject string before or after the regex match. This can be useful when the replacement text syntax is used to collect search matches and their context instead of making replacements in the subject string.
Some applications can insert the text matched by the regex or by capturing groups converted to uppercase or lowercase.
Some applications can use one replacement or another replacement depending on whether a capturing group participated in the match. This allows you to use different replacements for different matches of the regular expression.
The pages on this site are optimized for online reading. They don't print very well. Since many people prefer to read text printed on paper, all the information on this web site is now available as a downloadable PDF file.
Before you download the PDF, please make a donation to support this site first. If you donate 4.99 euro or more, you will be able to download the PDF instantly.
The PDF comes in two versions. One version is formatted for easy printing on ordinary letter-sized or A4 paper. The text spans about 300 pages. The other version is formatted on a smaller paper size but with the same font size for easy reading on tablets and e-readers with small screens. This version spans 400 pages. Compared with the cost of a typical paperback on regular expressions , 4.99 euro for what is arguably the world's most comprehensive tutorial and reference on regular expressions is certainly a bargain.
On this site, you can find everything you need to know about regular expressions:
Jan Goyvaerts is Chief Software Designer at his own software company Just Great Software . Just Great Software develops and publishes various software packages including PowerGREP, RegexBuddy, RegexMagic and EditPad Pro.
PowerGREP
is a knowledge worker's Swiss army knife for searching through, filtering and retrieving information from piles of files using regular expressions.
RegexBuddy
is your perfect assistant for working with regular expressions, making it easy to create, test and save regexes.
RegexMagic
allows you to generate regular expressions using powerful RegexMagic patterns, without using the cryptic regex syntax at all.
EditPad Pro
is a popular text editor with particularly strong support for regular expressions.
Feel free to use the form below to send the author your feedback about this site. If you found any errors on the site, feel something is not explained clearly, or if you know of an important regex-related topic not discussed here, please let him know. He tries to reply to inquiries as time allows.
Note that this is not a place to request technical support with regular expressions or any regex-related product. If you have a problem with PowerGREP, RegexBuddy, RegexMagic, or EditPad Pro, please use the appropriate technical support contact addresses.
This web site wouldn't be the web's premier source of information on regular expressions if it wasn't updated constantly. All new articles are announced on the Regex Guru blog. Subscribe to the Regex Guru RSS feed if you'd like to stay up-to-date with changes and new additions to your favorite regex site, and with the wonderful world of regular expressions in general. The blog will also give you behind-the-scenes scoops and other news that you won't find on this site.
Browser URL: http://www.regexguru.com/feed/
Newsreader URL: feed://www.regexguru.com/feed/